En este apartado nos centraremos en una de las herramientas necesarias para desarrollar proyectos multimedia: los tipos de lenguajes.
En 1981 apareció la denominada quinta generación de ordenadores, en la que se abandonó definitivamente el concepto de ordenador como una simple máquina de cálculo. A partir de ese momento la ordenación y comunicación de información prevalecen.
Los ordenadores personales pasan a ser un electrodoméstico más y la digitalización transforma la distribución de la música, la imagen, la telefonía, etc. Todo el mundo parece aventurar un mundo completamente digital.
Un ordenador puede dividirse en tres grandes partes:
Unidad Central de Proceso (CPU en inglés).
Memoria donde se almacenan datos e instrucciones para que sean procesados por la CPU.
Subsistema de entrada/salida que les permite interactuar con su entorno.
Se han creado diferentes lenguajes para comunicar a los ordenadores lo que deseamos que hagan.
 Lenguajes de programación
Lenguajes de programación
Un programa informático se escribe siguiendo una serie de reglas y una sintaxis definida por el lenguaje de programación utilizado. Existen distintos lenguajes de programación, cada uno con sus características concretas, que hacen que sean más o menos apropiados para conseguir nuestro programa final.
Veamos algunas de las diferentes tipologías de lenguajes.
Lenguajes de alto y bajo nivel
La CPU de un ordenador sólo sabe ejecutar un conjunto de instrucciones que están codificadas mediante ceros y unos, que es lo que se denomina lenguaje máquina.
Crear programas en este lenguaje resulta complejo para las personas, ya que la diferencia semántica entre el lenguaje máquina y el lenguaje natural es enorme.
Si le preguntamos a alguien que nos describa cómo transformar datos, su relato tendrá poco o nada que ver con un conjunto de instrucciones de suma, resta, desplazamiento y comparación de bits que son las únicas operaciones que saben hacer las CPU.
Cuando los primeros ordenadores aparecieron no había otro remedio que programar directamente en estos complicados lenguajes. Sin embargo, con la aparición de nuevos lenguajes de programación, se constató que un programador era capaz de producir una mayor cantidad de líneas de programa por unidad de tiempo. Por tanto, cuanto mayor sea la potencia semántica de las instrucciones, más productivo será su trabajo.
Poco a poco fueron creándose lenguajes de programación más lejanos a la semántica de la CPU y más cercanos a la semántica de las personas: los programadores.
El lenguaje máquina (ceros y unos) es el que se encuentra en el nivel más bajo de la categorización. Nos referimos a lenguajes de alto nivel como aquellos que se encuentran más cercanos a una «sintaxis humana». Un ejemplo de lista de lenguajes ordenada de bajo a alto nivel es: lenguaje máquina, ensamblador, C y Java.
Lenguajes compilados e interpretados
Otro concepto interesante es la manera como los lenguajes de programación se transforman en acciones que deben ser ejecutadas por el procesador:
Un lenguaje será interpretado si existe otro programa, denominado intérprete, que lea las instrucciones del lenguaje original y ponga en marcha rutinas que ejecuten lo que corresponde a esas instrucciones del programador.
Es importante remarcar que cuando un lenguaje es compilado, el resultado de este proceso es una tira de bits que sólo tiene sentido sobre la plataforma en la que se ha llevado a cabo la compilación. Esto se debe a que las instrucciones resultantes son de bajo nivel y sólo pueden ser ejecutadas por el mismo tipo de CPU con la que se obtenido el ejecutable. Si quisiéramos usar un programa compilado sobre un PC en un MAC, tendríamos que emplear el código fuente del programa, utilizar un compilador del lenguaje en la nueva arquitectura (MAC en este caso) y crear una nueva versión del ejecutable. Fijaos que no es necesario rescribir ni una línea de código, sólo hay que repetir el proceso de compilación.
Este problema de portabilidad del programa compilado entre plataformas desaparece en el caso de un programa interpretado, ya que la entrada del intérprete es el propio programa escrito por nosotros. Así, un programa escrito en Perl, podrá ser ejecutado tanto en MAC, Unix o PC compatible siempre que dispongamos en dicho ordenador del intérprete Perl.
Lenguajes orientados a sentencias y orientados a objetos
La evolución de los lenguajes de programación de bajo a alto nivel ha traído consigo una nueva tipificación de los mismos al evolucionar e integrar interfaces gráficas que les han permitido ser más cómodas para los programadores (user friendly).
Dentro de los lenguajes de programación podríamos mantener estos dos tipos:
Lenguajes orientados a sentencia. Siguen utilizándose, pero cada vez menos, ya que los lenguajes orientados a objetos gozan cada día de mayor popularidad. Se consideran una evolución de los lenguajes máquina pero con un mayor nivel semántico.
Ejemplos: Fortran, Basic, C, Pascal.
Lenguajes basados en la orientación a objetos. Son considerados lenguajes de programación de alto nivel semántico. Se basan en el concepto de que un objeto ofrece una serie de funciones para interactuar con el resto de elementos. Una de las ventajas de estos lenguajes es la facilidad de reutilizar código ya escrito y simplificar los desarrollos.
Ejemplos: Java y C++.
Lenguajes de autor
La línea que separa los lenguajes de programación de los lenguajes de autor es de difícil definición. Los lenguajes de autor integran habitualmente un lenguaje de programación que permite la potenciación de sus posibilidades.
Con otros, los basados en un paradigma de iconos, el desarrollo del producto será aún más fácil y rápido; algunos de ellos poseen ilimitadas capacidades de interacción, como el Quest. Otros sistemas de esta naturaleza son Authorware e IconAuthor.
Los sistemas de autor permiten que los cursos basados en computador puedan adaptarse fácilmente para la web.
Podríamos agruparlos en:
Lenguajes gráficos orientados a la estructura: se basan en una interfaz gráfica que se desarrolla a partir de una secuencia de acciones relacionadas entre sí (diagrama de flujo). Resultan especialmente útiles para la creación de programas de autoaprendizaje y tutoriales.
Ejemplos: AuthorWare, IconAuthor, Apple-MediaTool, Orgue, Course Builder.
Lenguajes basados en la orientación a objetos pero referidos a modelos hipermedia: permiten la construcción de libros y tarjetas electrónicas mediante la combinación de diferentes objetos predefinidos como pueden ser botones, sonidos, áreas activas, campos de texto, etc.
Ejemplos: Hypercard, Plus, Supercard, Toolbook, Linkway, Hyperstudio.
Lenguajes orientados a la presentación multimedia: son los que se usan en diferentes formatos de interfaz; fueron creados pensando únicamente en el desarrollo de animaciones o presentaciones. Su evolución, al incorporar lenguajes de programación, ha permitido ofrecer gran versatilidad. Asimismo, se están orientando cada vez más a un uso en la web y a sistemas on-line.
Ejemplos: Macromedia Director, Macromedia Flash, StoryBoard-Plus.
Veamos las características de algunos de los lenguajes de autor más utilizados en la actualidad.
AuthorWare
AuthorWare permite crear aplicaciones de aprendizaje interactivas en la red (e-learning) a través de un lenguaje de autor visual. Permite la integración de gráficos, sonidos, texto, animación y vídeos para su distribución en distintos formatos: redes corporativas, CD-ROM o Internet. También tiene facilidades integradas para monitorizar el progreso de los alumnos.
ToolBook
ToolBook es una alternativa a AuthorWare, y es una de las herramientas más potentes para la creación de simulaciones avanzadas y contenido interactivo, que es la base de cualquier solución e-learning.
Macromedia director
Macromedia Director es un sistema de autor, una herramienta de creación multimedia de posibilidades casi ilimitadas. Sin apenas necesidad de programar podemos desarrollar nuestras propias aplicaciones (presentaciones sencillas, juegos más complicados, enciclopedias interactivas, etc.). Si utilizamos el lenguaje propio de Director, Lingo, se aumentan las posibilidades.
La aplicación nos permite combinar gráficos, sonido, vídeo y prácticamente cualquier tipo de elemento multimedia en el orden que queramos; de hecho, el propio nombre del programa nos da una idea de cómo organiza el trabajo: la metáfora de uso del producto se basa en concebir la producción como si de una película se tratara, en la que nosotros actuamos como director, decidiendo qué actores entran a escena, cómo se sitúan y cuándo.
Lenguajes de marcas
En los lenguajes de marcas, el fichero que contiene el programa distingue dos tipos de objetos: las marcas y los datos sobre los que deben actuar las marcas.
Normalmente estos lenguajes son interpretados y las marcas implican opciones de formateo de los datos que las acompañan.
HTML
Antes de conocer más a fondo las características de este lenguaje de marcas vamos a repasar el origen del mismo y de la World Wide Web.
La historia de la World Wide Web es bastante joven puesto que comenzó en 1990 en Ginebra, Suiza. Tim Berners-Lee, informático británico en la Organización Europea de Investigaciones Nucleares CERN, inició con ayuda de algunos colegas un proyecto para desarrollar un nuevo sistema de intercambio de informaciones entre científicos a través de Internet. Se trataba de poder compartir documentos científicos en línea, manteniendo el formato de los textos y permitiendo el enlace de imágenes. Pero lo más importante era la idea de emplear una concepción hipertextual, de tal manera que los documentos pudieran contener enlaces a otros documentos, aun cuando éstos se encontrasen en diferentes servidores de Internet.
Para lograr estos objetivos, se concibió un nuevo formato de archivo, denominado HTML (Hypertext Markup Language) y se pensó un protocolo de transferencia, llamado HTTP (Hypertext Transfer Protocol). Para representar los archivos en línea se recurrió a un nuevo software: los navegadores. El proyecto fue bautizado World Wide Web (Red mundial) por el carácter de hipertexto.
Al mismo tiempo se comenzaron a configurar servidores WWW que deberían apoyar el nuevo protocolo http.
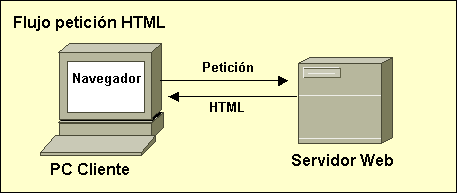
Una vez ubicados en la historia, ya podemos afirmar que HTML es el estándar de facto para la publicación de hipertextos en la World Wide Web y es un claro ejemplo de lenguaje de marcas.
Su definición no pertenece a ningún fabricante de software en concreto, es un software no propietario. Sin embargo, los fabricantes de navegadores han introducido pequeñas variaciones en el lenguaje que hacen que los documentos funcionen de forma diferente en los distintos navegadores. Para dejar de lado la universalidad original de este lenguaje, existen organismos que velan por su estandarización y comprueban que los contenidos programados cumplan estrictamente los estándares.
La manera de crear hipertextos con HTML varía desde un simple editor de textos a complejas herramientas WYSIWYG (What you see is what you get) en las que se diseñan páginas web según su aspecto final. Un ejemplo de dicha herramienta es el DreamWeaver de Macromedia.
La estructura básica de HTML es un conjunto de marcas diferenciadas del resto de texto por su inclusión entre paréntesis angulares (< >). Las marcas se abren con el nombre de la marca entre paréntesis angulares y se cierran mediante el nombre de la marca precedido por una barra (/) entre paréntesis angulares. Dichas marcas pueden anidar otras marcas y/o textos. En HTML varios espacios en blanco seguidos, tabuladores y los saltos de línea de los ficheros de texto no tienen significado. Deben especificarse con las marcas apropiadas.

Podemos estructurar un fichero HTML de manera que se aprecie visualmente la apertura de una marca y su cierre estableciendo diferentes niveles de tabulación.
<html>
<p> Y el resto es el <b>contenido</b> del documento </p>
La marca <html> comienza la definición de un documento, <body> indica el cuerpo del documento, <h1> es un tipo de párrafo de título, y <p> un párrafo estándar. Las marcas <i> y <b> implican que el texto que aparece afectado por ellas será visualizado en itálica (cursiva) y en negrita respectivamente. Su visualización sería algo similar a:
Este es el Título del documento
Y el resto del Contenido del documento.
De cara a facilitar la portabilidad de documentos HTML en diferentes plataformas, se pueden usar caracteres ASCII cuyo código sea menor de 128. Por lo tanto los caracteres internacionales (acentos, tildes, etc.) se marcan mediante una notación especial que comienza por el signo ampersand (&) y acaba por punto y coma (;). Por ejemplo la a minúscula acentuada en castellano se representa por «á»; y la letra ñ por «ñ».
Un documento HTML está asociado a una URL y puede referenciar tantos documentos HTML como se requiera usando hipertextos que los ligan con las URL respectivas.
<p>La página principal de la <a href="http://www.uoc.es">UOC</a> es un lugar a visitar.</p>
La página principal de la UOC es un lugar a visitar.
Asimismo, un documento HTML puede incluir referencias a cualquier tipo de elementos multimedia, imágenes, películas, etc., mediante la utilización de las marcas adecuadas.
<p>El esquema de la circulación sanguínea en el que se puede observar <img src="circulacion.gif"> el corazón como parte central del sistema.</p>
Para permitir la creación de páginas web más dinámicas, se enriqueció este lenguaje y se desarrolló el DHTML (Dynamic HTML) que veremos a continuación.
Un paso más avanzado en la obtención de interactividad con el usuario se consigue con la inclusión dentro de las páginas HTML de lenguajes como JavaScript, Java o Flash, de los que se hablará más adelante.
DHTML
El HTML dinámico es un término colectivo para designar una combinación de nuevas etiquetas y opciones, hojas de estilo y programación en Lenguaje de Marca de Hipertexto (HTML, siglas inglesas de Hypertext Markup Language) que permite crear páginas web más animadas y que respondan en mayor grado a la interacción del usuario que las versiones previas del HTML.
Ejemplos de las posibilidades de páginas creadas con DHTML podrían ser (1) que el color de un encabezado de texto cambie cuando el usuario pase el ratón sobre él o (2) permitir que el usuario «arrastre y suelte» una imagen hacia otro lugar de la pantalla. El HTML Dinámico permite que los documentos de la página web se vean y se comporten como aplicaciones del escritorio o producciones multimedia.
Aunque el HTML 4.0 está soportado tanto por los navegadores Netscape como Microsoft, algunas capacidades adicionales sólo sirven para uno u otro. El mayor obstáculo para el uso del HTML Dinámico es que, como no existe un estándar rígido, los sitios web deben crear varias versiones de cada página y ofrecer la apropiada para la versión de navegador del usuario.
Los principales conceptos y características del HTML Dinámico, desde el punto de vista de usuario son:
Hojas de estilos y capas
Una hoja de estilo en cascada o CSS (Cascading Style Sheets) describe las características de estilo por omisión (incluyendo el diseño de la página, el tipo y estilo de la fuente, y el tamaño de los elementos de texto, tales como encabezados y texto de cuerpo) de un documento o parte de él. Para las páginas web, una hoja de estilo también describe el color o imagen de fondo por omisión, los colores de los enlaces de hipertexto y, posiblemente, el contenido de una página. Las hojas de estilo ayudan a asegurar la coherencia en todas las páginas (o un grupo de ellas) en un documento o un sitio web. También facilitan la modificación de presentación de toda la web ya que, cambiando únicamente los archivos CSS de la misma, tendremos un nuevo estilo de presentación en todas aquellas páginas que utilicen las hojas de estilo modificadas, evitando tener que realizar los cambios de forma manual, página a página.
La distribución en capas (layering) es el uso de hojas de estilo alternas u otras aproximaciones para variar el contenido de una página proporcionando capas (layers) o niveles de contenido que puedan situarse por encima de secciones de contenido existentes, reemplazándolas o superponiéndose a ellas. Las capas pueden programarse para aparecer como parte de una presentación, vinculadas a una línea de tiempo predeterminada o como resultado de la interacción del usuario. Internet Explorer 4.0 de Microsoft implementa capas en todas las hojas de estilo. Netscape apoya la aproximación de hojas de estilo pero también ofrece un juego de etiquetas HTML (que Microsoft no soporta). Ambas aproximaciones están siendo analizadas por el Comité de Trabajo W3C, y las dos empresas dicen que apoyarán cualquiera que sea la aproximación recomendada que decida W3C.
Fuentes dinámicas
Netscape incluye fuentes dinámicas como parte del HTML dinámico. Esta característica del navegador Netscape permite a los diseñadores de páginas web incluir archivos de fuentes que contengan estilos, tamaños y colores específicos como parte de la página web para facilitar que las fuentes se descarguen junto con la página, consiguiendo que la elección de fuente ya no dependa de la tipografía disponible en el sistema del usuario.
No hay una especificación única para el HTML dinámico dado que es, en realidad, una combinación de varios elementos. Netscape y Microsoft tienen, cada uno, sus propias definiciones en sus sitios web respectivos.
XML
La versión 1.0 del lenguaje XML es una recomendación del W3C de febrero de 1998. Está basado en el anterior estándar SGML (Standard Generalized Markup Language, ISO 8879), cuya traducción significa «Lenguaje de Etiqueta Generalizado Estándar», que data de 1986 y está basado en el GML creado por IBM en 1969.
Esto significa que aunque XML pueda parecer moderno, sus conceptos están asentados y aceptados de forma amplia; XML está asociado a una recomendación internacional de modelización de la estructura interna de documentos (DOM, siglas inglesas de Document Object Model) aprobada en 1998.
SGML proporciona un modo coherente y preciso de aplicar etiquetas para describir las partes que componen un documento, permitiendo el intercambio de documentos entre diferentes plataformas. El problema que se atribuye a SGML es su excesiva dificultad. Manteniendo su misma filosofía, de él se derivó XML como subconjunto simplificado, eliminando las partes más engorrosas y menos útiles. Como su predecesor, XML es un metalenguaje, es decir, un lenguaje para definir lenguajes. Los elementos que lo componen pueden dar información sobre lo que contienen, no necesariamente sobre su estructura física o presentación como ocurre en HTML.
En una primera aproximación se puede decir que mediante XML también podríamos definir el HTML, con lo que podríamos considerar los siguientes conjuntos:
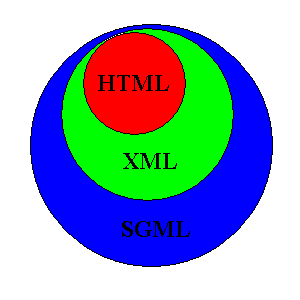
Una pregunta que nos podemos hacer es si XML será el sustituto de HTML. La respuesta es NO. Básicamente XML no ha nacido sólo para su aplicación en Internet, sino que se propone como lenguaje de bajo nivel (en el ámbito de la aplicación, no de la programación) para el intercambio de información estructurada entre diferentes plataformas. Se puede usar en bases de datos, editores de texto, hojas de cálculo, y casi cualquier cosa que podamos pensar.
A pesar de que XML no sustituirá al HTML, éste está mejorando algo de lo que HTML adolece desde hace tiempo: establece un estándar fijo y separa el contenido de su presentación. Esto significa que para ver un documento web no estaremos sujetos a la parte del estándar de hojas de estilo (CSS) que soporte el Navigator de Netscape o el IExplorer de Microsoft, ni al lenguaje de script del servidor y al modelo de objetos definido por el navegador en cuestión. Además, tampoco estaremos atados a la plataforma, pudiendo ver la misma información desde nuestro PC, desde un navegador textual, una lavadora, un microondas o un reloj con acceso a Internet, con presentaciones adecuadas a cada entorno.
La información estructurada por los ficheros XML está compuesta por palabras, imágenes y otros elementos multimedia junto con una indicación del papel que juega cada elemento dentro de la estructura del documento.
Mediante esta estructuración podemos contextualizar los elementos y lograr diferenciar, por ejemplo, un texto que aparece en el título del documento de otro que aparece al pie de una figura. Ésta es, por ejemplo, una gran ventaja sobre la información difundida en HTML, donde se pierde la noción del contexto a fin de incluirla en buscadores.
El concepto de documento en XML va más allá de lo que podamos pensar en un primer momento. Lejos de ser otra manera de escribir información con un formato más o menos agradable visualmente, un documento XML puede representar ecuaciones matemáticas, transacciones económicas de comercio electrónico, definiciones de piezas mecánicas, especificaciones de maquinaria de cualquier tipo, etc.
Una gran ventaja que ofrecen los documentos XML es que permiten estructurar la información de manera que pueden obtenerse diversas y variopintas visiones de ella: bases de datos, documentos impresos, documentos sonoros, etc. Todo ello es posible gracias a los programas que interpretan los documentos XML.
Pero la mayor ventaja de los documentos XML es, sin duda, la separación existente entre el contenido y la presentación gráfica del mismo.
Reflexionemos sobre la gran ventaja que supone para un editor multimedia poder actualizar una obra en XML y ser capaz de obtener automáticamente la versión correspondiente en HTML, PDF, WAP, texto braille y audible (mediante programas de síntesis de voz). Este enorme potencial hace que XML gane cada día más terreno.
Para entender el porqué de un lenguaje de marcas tan innovador se debe tener en cuenta que se creó para poder difundir documentos altamente estructurados en Internet. Los requerimientos que se tuvieron en cuenta en su creación fueron diversos:
Debía ser fácil usar XML en Internet. Los usuarios debían poder visualizar esos documentos tan fácil y rápidamente como los documentos HTML. Actualmente no es una realidad, pero tan sólo debemos esperar a que los navegadores de XML hayan evolucionado tanto como los navegadores de HTML.
XML debía dar soporte a una amplia variedad de aplicaciones.
Debía ser sencillo escribir programas que procesen documentos XML. En términos prácticos, es deseable que un ingeniero en informática con escasa experiencia profesional no tarde más de dos semanas en crear un programa que procese documentos XML.
Se debería mantener en un mínimo, idealmente cero, la cantidad de características opcionales de XML, cuya aparición no hace sino crear problemas de compatibilidad a la hora de compartir documentos.
Los documentos XML deberían ser legibles sin necesidad de un navegador para que cualquier persona con conocimientos de XML pudiera hacerse una idea general del contenido del documento abriéndolo con un simple editor de textos.
A primera vista un documento XML puede parecer idéntico en estructura a un documento HTML ya que ambos son un conjunto de marcas entre paréntesis angulares y textos a los que se aplican. Pero la gran diferencia es que las marcas de XML no vienen predefinidas como en HTML.
<?xml version="1.0"?>
<cita>
<texto>Hay más llantos en la Tierra por favores concedidos que por favores negados<texto>
<autor> Santa Teresa de Jesús </autor>
<pausa/>
<moraleja> Cuidado con lo que pides porque a lo mejor lo consigues </moraleja>
</cita>
De este pequeño documento en XML, resulta interesante poner de relieve:
El documento comienza con la instrucción de proceso <?xml ...?> la cual no es imprescindible según el estándar, pero informa de que se trata de un documento XML y de la versión del mismo.
El significado de cada una de las marcas es arbitrario y debe especificarse aparte.
Los elementos vacíos tienen una sintaxis modificada y empiezan por (<) y acaban por (/>). Mientras que la mayoría de las marcas delimitan algún contenido, los elementos vacíos son simplemente marcas que implican alguna acción. Sería similar a las marcas <br> o <hr> de HTML que implican un salto de línea o el dibujo de una raya horizontal.
Los documentos XML tienen seis tipos de marcas: elementos, referencias a entidades, comentarios, instrucciones de proceso, secciones marcadas y declaraciones de tipo de documento (DTD).
En vista de la libertad que permite la definición de un documento XML, es imprescindible que quien deba interpretar el contenido sepa cómo hacerlo. Para ello los documentos XML deben referir a un DTD.
DTD son las siglas inglesas de Document Type Definition, y es la definición de los elementos del documento XML y su relación entre ellos, sus atributos, posibles valores, etc. Es una especie de definición de la gramática del documento. Cuando se procesa cualquier información formateada mediante XML lo primero es comprobar si está bien formada, y luego, si incluye o referencia a un DTD, comprobar que sigue sus reglas gramaticales.
Es una buena práctica escribir el DTD como un documento separado para:
No tener que incluir el DTD en cada documento XML que usa esa definición.
Estandarizar la descripción de los elementos usando DTD que se entiendan como válidos para un ámbito de conocimiento, para un conjunto de empresas, etc. Ya existen tales estándares para ámbitos como la creación de libros (DocBook) o el intercambio de fórmulas matemáticas (MML).
Hay dos tipos de documentos XML:
Bien formados: son todos los que cumplen las especificaciones del lenguaje sin estar sujetos a unos elementos fijados en un DTD. De hecho, los documentos XML deben tener una estructura jerárquica muy estricta y los documentos bien formados deben cumplirla.
Válidos: además de estar bien formados, siguen una estructura y una semántica determinada por un DTD; sus elementos y sobre todo la estructura jerárquica que define el DTD, además de los atributos, deben ajustarse a lo que el DTD dicte.
Presentación y transformación de XML: CSS y XSLT
Ya hemos visto anteriormente que un documento XML no lleva información sobre su presentación gráfica; sin embargo, está claro que necesitamos un mecanismo para poder realizar la presentación de la información del documento. Esto se puede conseguir a través de dos mecanismos:
1) Hojas de estilo CSS
Como hemos visto, este lenguaje de hojas de estilo se utiliza normalmente para controlar la presentación de documentos HTML, pero también se puede utilizar con documentos XML.
Éstas son las principales ventajas y desventajas respecto al lenguaje que veremos a continuación:
Ventajas:
Fácil de aprender y utilizar y de amplia difusión entre los desarrolladores.
Consume poca memoria y tiempo de proceso, pues no construye una representación en árbol del documento.
Muestra el documento según se va procesando.
Desventajas:
Sólo sirve para visualizar documentos en un navegador.
No permite realizar manipulaciones sobre el documento, tales como añadir y borrar elementos, realizar ordenaciones, etc.
Sólo permite acceder al contenido de los elementos y no a los atributos, instrucciones de proceso, etc.
Utiliza una sintaxis diferente a la del XML.
2) Lenguaje XSLT
Para subsanar las limitaciones presentadas por las hojas de estilo CSS, el consorcio W3C se puso a trabajar en la nueva recomendación XSL (eXtensible Stylesheet Language). Según el W3C, XSL es «un lenguaje para transformar documentos XML», así como un vocabulario XML para especificar la semántica de formateo de documentos.
En definitiva, además del aspecto que ya incluía CSS referente a la presentación y estilo de los elementos del documento, añade una pequeña sintaxis de lenguaje de programación para poder procesar los documentos XML de forma más cómoda.
XSL se compone de dos partes diferenciadas:
XSLT: lenguaje para transformar documentos XML en otro formato (otro XML, HTML, DHTML, texto plano, PDF, RTF, Word, etc.).
XSL-FO: especificación que indica cómo deben ser los objetos de formato para convertir XML a formatos binarios (PDF, Word, imágenes, etc.).
Esta manipulación la gestiona un programa especial, el procesador XSLT. Existen distintos procesadores disponibles, como Xalan, del proyecto en colaboración de código abierto Apache.
Las ventajas y desventajas de este lenguaje son:
Ventajas:
La salida no tiene por qué ser HTML para visualización en un navegador, sino que puede estar en muchos formatos.
Permite manipular de muy diversas maneras un documento XML: reordenar elementos, filtrar, añadir, borrar, etc.
Permite acceder a todo el documento XML, no sólo al contenido de los elementos.
XSLT es un lenguaje XML, por lo que no hay que aprender nada especial acerca de su sintaxis.
Desventajas:
Su utilización es más compleja.
Consume cierta memoria y capacidad de proceso, pues se construye un árbol con el contenido del documento.
Las formas de uso de este lenguaje son múltiples, aunque éstas son las más habituales:
Visualizar directamente en un navegador el documento XML que tiene asociada una hoja XSLT. El navegador debe tener incorporado un procesador XSLT.
Ejecutar el procesador XSLT independientemente del navegador. Se le pasan las entradas necesarias (fichero origen y hoja XSLT a utilizar) y genera la salida en un fichero, con el que podemos hacer lo que queramos.
Realizar las transformaciones dentro de un programa en el servidor y enviar a los clientes sólo el resultado de la transformación.
A partir del documento XML inferior, vamos a realizar una hoja de estilo XSLT que mostrará los datos en una tabla con las siguientes características: las empresas estarán ordenadas por el precio de cotización, los precios superiores a 75 aparecerán en azul y los inferiores a 25 en rojo, las empresas del índice general se marcarán con un asterisco (*), con una explicación debajo de la tabla. El título del documento contendrá el día y hora de la información:
<?xml version="1.0" ?>
<Bolsa xmlns="http://www.labolsa.com"
dia="5-7-2001"
hora="11:34">
<Empresa indice="general">
<Nombre>General Motors</Nombre>
<Simbolo>GMO</Simbolo>
<Precio>28.875</Precio>
</Empresa>
<Empresa indice="tecno">
<Nombre>Adobe</Nombre>
<Simbolo>ADB</Simbolo>
<Precio>92.250</Precio>
</Empresa>
<Empresa indice="tecno">
<Nombre>Microsoft</Nombre>
<Simbolo>MSF</Simbolo>
<Precio>20.313</Precio>
</Empresa>
<Empresa indice="general">
<Nombre>Coca-Cola</Nombre>
<Simbolo>COC</Simbolo>
<Precio>38.895</Precio>
</Empresa>
<Empresa indice="tecno">
<Nombre>Sun Microsystems</Nombre>
<Simbolo>SUN</Simbolo>
<Precio>45.119</Precio>
</Empresa>
</Bolsa>
Ésta es la hoja de estilo XSLT que nos presentará el resultado con las características comentadas:
<?xml version="1.0" encoding="ISO-8859-1" ?>
<xsl:stylesheet xmlns:xsl="http://www.w3.org/1999/XSL/Transform"
- xmlns:Bolsa="http://www.labolsa.com"
version="1.0">
<xsl:template match="Bolsa:Bolsa">
<html>
<head>
<title>La bolsa el <xsl:value-of select="@dia" /> a las
<xsl:value-of select="@hora" /></title>
</head>
<body>
<table border="2" align="center">
<tr>
<th>Símbolo</th>
<th>Nombre</th>
<th>Precio</th>
</tr>
<xsl:for-each select="Bolsa:Empresa">
<xsl:sort select="Bolsa:Precio" order="descending"/>
<tr>
<td>
<xsl:value-of select="Bolsa:Simbolo"/>
</td>
<td>
<xsl:value-of select="Bolsa:Nombre"/>
<xsl:if test="@indice='general'"> (*)</xsl:if>
</td>
<td>
<xsl:choose>
<xsl:when test="Bolsa:Precio > 75">
<font color="blue"><xsl:value-of select="Bolsa:Precio"/></font>
</xsl:when>
<xsl:when test="Bolsa:Precio < 25">
<font color="red"><xsl:value-of select="Bolsa:Precio"/></font>
</xsl:when>
<xsl:otherwise>
<xsl:value-of select="Bolsa:Precio"/>
</xsl:otherwise>
</xsl:choose>
</td>
</tr>
</xsl:for-each>
</table>
<p align="center">(*) Estas empresas son del índice general</p>
</body>
</html>
</xsl:template>
</xsl:stylesheet>
Las expresiones que pueden aparecer en los atributos select, match o test de los elementos incluidos en XSLT siguen el lenguaje XPath. La especificación XPath contiene muchas características; aunque aquí no las explicaremos, sí es interesante comentar que con este lenguaje se pueden crear funciones tan complejas como se requiera.
XHTML
XHTML es una reformulación del tipo de documento HTML como aplicaciones de XML. Su finalidad es su uso como lenguaje de contenidos que, a su vez, sea conforme a XML por lo que, siguiendo algunas sencillas directrices, funcione tanto en agentes de usuario conformes a HTML (por ejemplo los navegadores) como en herramientas estándares XML.
La familia XHTML es el siguiente paso en la evolución de Internet. Al migrar hacia XHTML, los desarrolladores de contenidos web entran en el mundo de XML con todos los beneficios de éste, a la vez que se aseguran la compatibilidad con agentes de los usuarios pasados y futuros.
