Detector automįtico de interacciones
Enunciado:
En un estudio sobre un determinado buscador de Internet, se realizó una encuesta electrónica entre los clientes del servicio que da este buscador para que diesen su valoración sobre la utilidad que percibķan con su uso. La encuesta fue contestada por 200 usuarios de este buscador.
A estos usuarios, aparte de pedirles que lo valorasen de 1 a 10, de menos a mįs valorado, se les pedķa que dijeran en qué segmento de edad se encontraban (de 18 a 30 ańos, de 31 a 45, mįs de 45) y el lugar desde donde se conectaban habitualmente a Internet (desde el trabajo o desde casa).
Para poder trabajar con los resultados de la encuesta, se realizó la codificación siguiente:
|
Edad |
Código |
|
De 18 a 30 |
1 |
|
De 31 a 45 |
2 |
|
Mįs de 45 |
3 |
|
Lugar conexión |
Código |
|
Trabajo |
1 |
|
Casa |
2 |
A partir de los resultados de la encuesta, se pide que hagįis una detección automįtica de interacciones para configurar grupos homogéneos (diferentes entre ellos) que tengan una valoración parecida sobre el buscador objeto de estudio.
Solución:
En primer lugar, ejecutad el programa Minitab con los datos del caso prįctico.
Primero nos planteamos las cuatro dicotomķas siguientes:
D1: De 18 a 30 – Mįs de 30
D2: De 31 a 45 – De 18 a 30 y Mįs de 45
D3: Mįs de 45 – Menos de 45
D4: Trabajo - Casa
Para recoger estas dicotomķas con Minitab, crearemos tres nuevas variables, D1, D2 y D3, de forma que, por ejemplo, el valor de la variable D1 vale 1 para un encuestado que tiene de 18 a 30 ańos y vale 0 si tiene mįs de 30 ańos. Para crear estas variables, hacemos lo siguiente:
Calc/Make Indicator Variables
Y a continuación introducimos la columna "Grupo de edad" en la ventana Indicator variables, y después los nombres de las columnas en las que queremos almacenar los 1 y 0 de las variables D1, D2 y D3.
Para la variable D4 no es necesario realizar ninguna transformación, porque ésta ya es dicotómica.
Acto seguido procedemos a realizar cuatro anįlisis de la varianza utilizando como variable respuesta la valoración de los usuarios y como factores (variable explicativa) D1, D2, D3 y D4, respectivamente.
Para realizarlos, tenemos que hacer:
Stat/ANOVA/One-way
En la pantalla que aparecerį hay que poner la variable sobre la que se ha preguntado (en este caso, sobre la valoración del buscador) en el recuadro Response, y la columna correspondiente al factor en el recuadro Factor.
Al hacer OK, obtendremos la siguiente salida de Minitab:
One-way Analysis of Variance
Analysis of Variance for Valoraci
Source DF SS MS F P
D1 1 179,70 179,70 24,12 0,000
Error 198 1475,09 7,45
Total 199 1654,80
Individual 95% CIs For Mean
Based on Pooled StDev
Level N Mean StDev --+---------+---------+---------+----
0 124 4,363 2,786 (----*---)
1 76 6,316 2,634 (-----*-----)
--+---------+---------+---------+----
Pooled StDev = 2,729 4,0 5,0 6,0 7,0
Los resultados que debemos considerar de esta salida son, en primer lugar, el valor del estadķstico F, que es un indicador de la diferencia que hay, en este caso, entre los grupos "De 18 a 30" y "Mįs de 30 ańos". En segundo lugar, deberemos considerar la valoración media de cada uno de los dos grupos, lo que nos ayudarį a conocer el comportamiento de cada uno de los segmentos en los que quedarį dividido el mercado.
En la tabla siguiente se recogen los principales resultados de los cuatro ANOVA:
|
Dicotomķas |
F |
Grupos |
N |
Valoración media |
|
D1 |
24,12 |
De 18 a 30 |
76 |
6,32 |
|
D2 |
0,24 |
De 31 a 45 |
59 |
4,95 |
|
D3 |
20,66 |
Mįs de 45 |
65 |
3,83 |
|
D4 |
2,72 |
Trabajo |
100 |
4,77 |
De estos resultados, lo que primero se observa es que el valor mayor del estadķstico F se obtiene cuando se comparan las valoraciones que hacen los grupos "De 18 a 30" y "Mįs de 30". Por tanto, ya podemos decidir la primera segmentación:

Ahora, dentro de cada uno de los dos segmentos que nos han aparecido, debemos continuar distinguiendo entre grupos.
Primer segmento: De 18 a 30
Por lo que respecta al primer segmento, debemos pasar a utilizar la segunda variable explicativa, la conexión. En primer lugar, para trabajar con este segmento, deberemos extraer de toda la encuesta los resultados correspondientes sólo a encuestados que estįn en este grupo.
Para hacerlo, debemos proceder de la manera siguiente:
Manip/Subset Worksheet
En la ventana que se abrirį se deben marcar las opciones Specify wich rows to include y Rows that match. Y en este segundo caso debemos introducir la condición, Condition..., que nos permitirį trabajar con los resultados que queremos. En nuestro caso, dado que nos centramos en el segmento de usuarios de edades entre 18 y 30 ańos, es suficiente poner la condición de que la variable D1 valga 1, ya que éste es el valor que toma esta variable cuando un encuestado se sitśa en esta franja de edad.
Por otro lado, en el recuadro Name podemos poner el nombre que le queramos dar al conjunto de datos. En este caso hemos puesto "De 18 a 30".

Ahora, trabajando con sólo los datos del segmento considerado, realizamos un ANOVA con la variable "Valoración" y el factor "Conexión", directamente. El resultado es el siguiente (recordad que el código 1 indicaba conexión desde el trabajo y que el código 2 indicava conexión desde casa):
One-way Analysis of Variance
Analysis of Variance for Valoraci
Source DF SS MS F P
Conexión 1 4,06 4,06 0,58 0,448
Error 74 516,36 6,98
Total 75 520,42
Individual 95% CIs For Mean
Based on Pooled StDev
Level N Mean StDev -----+---------+---------+---------+-
1 34 6,059 2,674 (--------------*--------------)
2 42 6,524 2,616 (-------------*------------)
-----+---------+---------+---------+-
Pooled StDev = 2,642 5,40 6,00 6,60 7,20
Puesto que la variable "Conexión" ya era dicotómica, en este punto del estudio no podremos decidir entre posibles segmentaciones (como hemos hecho antes eligiendo aquella que tenķa la F mayor).

Por lo que respecta a este segmento del mercado, ya habremos acabado. Ahora hay que seguir con el otro, el de usuarios mayores de 30 ańos.
Segundo segmento: Mįs de 30
En lo concerniente a este segundo segmento, debemos pasar a utilizar la segunda variable (como en el caso anterior), pero ademįs debemos tener en cuenta que dentro de este segmento se encuentran, por un lado, los que tienen entre 31 y 45 ańos y, por otro, los que tienen mįs de 45 ańos.
Para trabajar con este segmento, deberemos extraer de toda la encuesta los resultados correspondientes sólo a encuestados que estįn en este grupo de mįs de 30 ańos. Para hacerlo, debemos proceder como en el caso anterior:
Manip/Subset Worksheet
Pero ahora poniendo la condición de que D1 sea igual a 0.
Para este segmento sķ que se plantean diferentes dicotomķas:
E1: De 31 a 45 – Mįs de 45
E2: Conexión desde el trabajo – Conexión desde casa
De la misma manera que hemos hecho en la primera segmentación, en este caso deberemos hacer dos ANOVA, uno para E1 y otro para E2 y elegir la segmentación segśn el mayor valor del estadķstico F.
Para la primera dicotomķa utilizaremos el factor D2. Dado que estamos trabajando con usuarios de mįs de 30 ańos, un valor 1 de esta variable nos indica un encuestado que se encuentra en la franja de edad de 31 a 45 ańos. Por otro lado, un valor 0 nos indicarį que el usuario tiene mįs de 45 ańos.
Para la segunda dicotomķa, igual que hemos hecho en el caso anterior, utilizaremos el factor "Conexión" directamente.
Los resultados obtenidos son los siguientes:
|
Dicotomķas |
F |
Grupos |
N |
Valoración media |
|
E1 |
5,15 |
De 31 a 45 |
59 |
4,95 |
|
E2 |
1,20 |
Trabajo |
66 |
4,11 |
Por tanto, puesto que el valor mįs elevado lo hemos obtenido por la dicotomķa E1, la segmentación continuarį por las edades y no por el lugar desde donde se conectan.

Finalmente, para acabar la segmentación, deberķamos continuar por las dos śltimas cajas, centrįndonos en el segmento de 31 a 45 ańos y en el de mįs de 45 ańos. Procederķamos de la misma manera que lo hemos hecho con el segmento de 18 a 35 ańos: utilizando la variable dicotómica "Conexión". El diagrama final serķa el siguiente:
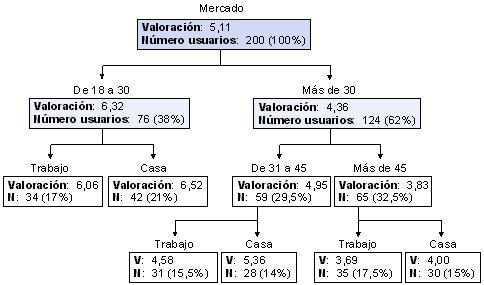
Conclusiones
Como hemos podido ver, usando el detector de interacciones, hemos podido realizar una segmentación del mercado agrupando elementos parecidos (es decir, usuarios con caracterķsticas parecidas), de forma que entre ellos, entre los grupos, haya el mayor nśmero posible de diferencias.
Asķ, mientras el colectivo de usuarios comprendidos en la franja de los 18 a los 30 ańos es el que mejor valora el buscador, con una puntuación media de 6,32, de éstos, los que hacen una valoración mįs alta, con un 6,52, son quienes se suelen conectan desde casa (el 21% del total).
Por otro lado, si seguimos la otra rama del įrbol, llegaremos a encontrar al grupo de usuarios que menos lo valoran. Concretamente, se trata de quienes tienen mįs de 45 ańos y se conectan habitualmente desde el trabajo, que son un 17,5% del total. Éstos valoran el buscador sólo con un 3,69.

