¢QuÕ es el SGML? |
||
BÃsicamente, SGML (Standard Generalized Markup Language) es un modelo internacional que permite estandarizar y definir formalmente un documento electrµnico, independientemente del software, la aplicaciµn o el sistema que se utilice. Esto quiere decir que el SGML permite, como metalenguaje que es, definir diferentes estructuras mediante marcas descriptivas con el fin de describir los contenidos de los documentos. Hay que especificar que el SGML no implica una descripciµn de la apariencia fÚsica del documento, ya que esta acciµn la llevan a cabo las distintas plataformas que interpretan el documento, como por ejemplo el navegador. El SGML define e identifica las diferentes estructuras de contenido del documento segºn la finalidad o el sentido que tienen.
EL SGML fue definido por la ISO (International Organization for Standarization), concretamente por la norma ISO 8879, aprobada en el aþo 1986, como modelo abierto para la creaciµn de documentaciµn electrµnica, que unifica la aplicaciµn de los conceptos de anotaciµn estructural de los documentos. No es un formato de almacenamiento ni un procesador de textos, es un metalenguaje con el cual es posible crear y definir distintos lenguajes de anotaciµn o marcas, con los cuales se puede procesar, gestionar y almacenar un texto, como es el caso de HTML, que se utiliza para la descripciµn de documentos en web.

Sin embargo, antes de entrar en aspectos mÃs concretos de SGML, es preciso hacer Õnfasis en los diferentes conceptos que afectan a un documento. Podemos decir que prÃcticamente todos los documentos que leemos tienen algºn tipo de estructura. En la parte superior de un texto, vemos un pÃrrafo mÃs destacado que el resto; despuÕs un bloque de texto y, dentro de Õste, algunas letras en cursiva, otras en negrita, y en medio de todo, alguna imagen. Todo eso lo interpretamos por deducciµn, y de esta forma el texto destacado en la parte superior lo asociaremos al tÚtulo, y el resto de texto lo asociaremos por su disposiciµn y distribuciµn por la pÃgina.

A partir de este punto, hay que definir las diferentes formas en las que es posible analizar un documento. Por una parte, tendremos que hablar del marcaje descriptivo y, por otra, del marcaje procedural. AsÚ, por marca, palabra definida para describir anotaciones dentro de un texto, entendemos todo aquello que no es contenido en un documento. En su forma primigenia, la marca se referÚa a las anotaciones manuales que se hacÚan para aþadir al texto las instrucciones, que hacÚan referencia a su forma, cµmo tenÚa que presentarse formalmente y quÕ tipografÚa debÚa utilizar. Este tipo de marcaje se conoce como marcaje procedural.
En este contexto, el marcaje define todo aquello que es parte integrante de un documento electrµnico, pero que no es texto imprimible. El fichero donde se almacena uno de estos documentos es ilegible al estar desplegado con un editor o procesador de textos. Recordemos que los procesadores de texto aþaden multitud de anotaciones a un documento que especifican las caracterÚsticas de la versiµn papel. AsÚ, un lenguaje de marcas està formado por reglas que describen cµmo tienen que realizarse las marcas, bajo quÕ condiciones estÃn permitidas y cuÃl es su significado. De este modo, por ejemplo, la mayor parte de los procesadores de texto implementan su propio lenguaje de marcas y formato.
Las marcas cumplen dos objetivos fundamentales:
|
Separar los diferentes elementos lµgicos de un documento. |

|
Especificar las operaciones tipogrÃficas que tienen que ejecutarse sobre estos elementos lµgicos. |
Los elementos lµgicos son todos aquellos derivados de operaciones tipogrÃficas que se aplican a la forma del texto, como por ejemplo la cursiva, la negrita, un pÃrrafo, un tipo de letra determinado, un tamaþo concreto, una nota a pie de pÃgina, etc. Es decir, todo aquello que se pueda resaltar y definir sobre el resto del texto en formato plano.
De esta manera, el lenguaje de marcaje procedural es el que contiene las marcas que describen las diferentes operaciones tipogrÃficas que pueden aplicarse a cada uno de los elementos del documento. AquÚ tenÕis una representaciµn grÃfica del significado:
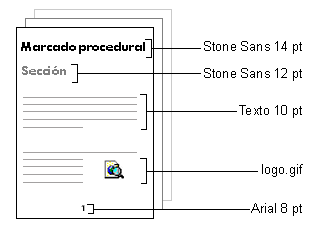

Por otro lado, el lenguaje descriptivo define un marcaje que describe ºnicamente la estructura lµgica del documento. Las marcas estructurales no sirven en ningºn momento para designar cµmo debe aparecer el texto en el documento; especifican simplemente el tipo de elemento que es y no su apariencia. La base de este lenguaje consiste en que conceptualmente sµlo tiene que encargarse de estructurar la informaciµn del documento segºn unas marcas descriptivas, totalmente separado de lo que implica el estilo del documento. De hecho, el SGML no autoriza el marcaje procedural dentro de su sintaxis, ya que la apariencia externa del documento no es un elemento que aporte ningºn provecho al lenguaje de marcas, si hablamos estructuralmente.
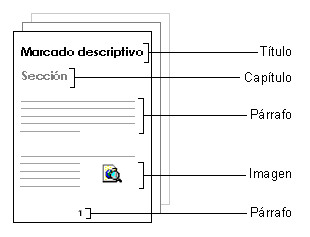
El lenguaje descriptivo identifica con marcas los elementos que forman el documento, como por ejemplo los tÚtulos, los pÃrrafos, las secciones, etc., tal y como se muestra en la imagen siguiente:
En general, los lenguajes procedurales para describir documentos como troff, por ejemplo, representan una sobrecarga de formatos con una complejidad enorme, que en ningºn caso hacen referencia al formato de lo que se està escribiendo. Por ejemplo, si queremos especificar un trozo de texto tabulado, en troff serÚa muy complejo:
.sp 1; .ss; sin 12 - 12
Mientras que el mismo en lenguaje SGML se simplifica especificando:
<BLOCKQUOTE> ÀEsto estarà tabulado! </BLOCKQUOTE
Por suerte, la mayorÚa de los lenguajes de marcaje son una combinaciµn de los dos tipos de lenguaje de marcas. Por ejemplo, Word o WordPerfect incluyen estilos con los cuales podemos definir tanto el nivel estructural como procedural del documento, es decir, los diferentes tÚtulos, pÃrrafos, anotaciones, etc. y, al mismo tiempo, la presentaciµn, la tipografÚa, los colores, los tamaþos, etc.
Las marcas descriptivas son de base mÃs rica que las procedurales. En primer lugar, las procedurales suponen menos informaciµn sobre los elementos del documento. Dos elementos estructuralmente diferentes pueden estar marcados proceduralmente de la misma manera, aunque representen conceptos distintos. En cambio, las marcas estructurales, ya que no definen apariencia, permiten que dos elementos lµgicamente distintos se marquen de forma diferente, sin tener en cuenta si en la versiµn impresa del documento los dos utilizarÃn las mismas operaciones tipogrÃficas.
Las marcas descriptivas requieren una sola etiqueta para describir elementos, como por ejemplo los tÚtulos, y una funciµn para describir cµmo tiene que traducirse este elemento con el fin de producir la versiµn final con la inclusiµn una sola vez de elementos de marca procedurales. En documentos simples, esto no parece tener mucho interÕs; sin embargo, cuando hablamos de colecciones de documentos extensas y complejas la cosa cambia considerablemente.
Con esta filosofÚa, el SGML aporta una serie de ventajas considerables para generar documentos electrµnicos:
| Al permitir crear lenguajes descriptivos de marcas, hace Õnfasis en el marcaje estructural y no procedural, ya que no incluye informaciµn sobre cµmo tienen que interpretarse las marcas; esto se debe a que su objetivo es describir las unidades lµgicas del documento y no cµmo tiene que presentarse. |
| Formaliza la concepciµn de tipos de documentos gracias a la definiciµn de tipos de documento (DTD), que describe una clase de documentos con unas caracterÚsticas comunes. Dado que no implica un conjunto de convenciones de marcas, permite un conjunto de etiquetas flexibles y sobradamente definibles por el creador. |
| El contenido siempre serà independiente del sistema en que se visualice; es decir, evita la dependencia de los conjuntos de caracteres, como ASCII o EBCDIC, especÚficos para fabricantes de equipos informÃticos. El SGML utiliza caracteres encontrados en la mayorÚa de los sistemas y define mecanismos para utilizar o transformar otros caracteres especÚficos poco comunes (denominados referencias de entidad), con lo cual permite una legibilidad perfecta tanto para el creador como para el ordenador. |
| En SGML, el etiquetado es lµgico y no utiliza un cµdigo crÚptico para denominar los diferentes elementos del documento, los cuales quedan delimitados por marcas que indicarÃn el inicio y el final de los objetos lµgicos. |
¢CuÃl es el funcionamiento del SGML?
Cualquier documento puede delimitarse en diferentes aspectos, como por ejemplo la estructura, el contenido y el estilo. El SGML permite separar los tres elementos de su sintaxis, y se dedica especialmente a definir la relaciµn entre la estructura y el contenido.
Definimos la estructura del documento con lo que puede considerarse el corazµn del SGML, el DTD (Document Type Definition), que es una descripciµn formal de una clase de documento y permite verificar si un documento es miembro de una clase determinada. Esta verificaciµn la realiza mediante un analizador en el plano lÕxico y sintÃctico de SGML, que utiliza como entrada el DTD y el documento, y comprueba si este ºltimo es miembro o no de la clase definida por la primera.
El DTD describe la estructura jerÃrquica de un documento, de la misma manera que el esquema base de una base de datos describe los diferentes tipos de informaciµn que arregla, asÚ como las relaciones que se establecen entre los campos. El DTD proporciona un Ãmbito de trabajo para los diferentes elementos que constituyen el documento (capÚtulos, tÚtulos, secciones, etc.). El DTD tambiÕn especifica las normas que rigen las relaciones entre los elementos (por ejemplo, que el encabezamiento tiene que ser la parte constitutiva del documento en primera instancia o que un listado de menº debe contener uno o mÃs elementos dispuestos de una manera especÚfica dentro del documento). Gracias al DTD podemos etiquetar los documentos con una codificaciµn genÕrica y vÃlida para cualquier plataforma.
Por ejemplo, supongamos que queremos llevar a cabo una recopilaciµn de recetas de cocina de diferentes libros con sus descripciones, orÚgenes, ingredientes, etc., y que deseamos hacerlo de una manera correcta para todas las plataformas. Creamos un documento en SGML y definimos el DTD correspondiente (lo denominaremos RCP, Recetas de Cocina Personales) en los diferentes elementos que determinamos segºn el contenido que estructuraremos, y que ya conocemos. El DTD podrÚa ser Õste:
<!DOCTYPE RCP [
<!ELEMENT RCP - - (titulo, metainformacion, contenido)>
<!ELEMENT p - O (#PCDATA)>
<!ELEMENT titulo - - (#PCDATA)>
<!ELEMENT metainformacion - - (editor+, prologo?)>
<!ELEMENT editor - - (#PCDATA)>
<!ELEMENT prologo - - (#PCDATA, P+)>
<!ELEMENT glosario - - (entrante)>
<!ELEMENT entrada - O (nombre, descripcion)>
<!ELEMENT utensilios - - (nombre, descripcion)>
<!ELEMENT nombre - O (#PCDATA)>
<!ELEMENT descripcion - O (#PCDATA)>
<!ELEMENT contenido - - (receta+)>
<!ELEMENT receta - O (origen & dificultad & tiempo & tipo & autor? & (u-requeridos*) & l-ingredientes & preparacion & p+)>
<!ELEMENT origen - - (#PCDATA)>
<!ATTLIST origen region (oriental | asiatico | europeo | nortemerica | sudamerica) #REQUIRED>
<!ELEMENT dificultad - - (facil | media | dificil)
<!ELEMENT tiempo - - (#PCDATA)>
<!ELEMENT tipo - - (entrante | plato | postre)>
<!ELEMENT autor - - (#PCDATA)>
<!ELEMENT u-requeridos - - (nombre)
<!ELEMENT porciones - - (#PCDATA)>
<!ATTLIST porciones tamaþo (grande | mediano | pequeþo) #IMPLIED>
<!ELEMENT l-ingredientes - - (item+)>
<!ELEMENT item - - (cant? & tamaþo? & ingrediente)
<!ATTLIST item neces (opcional) #IMPLIED>
<!ELEMENT cant - - (#PCDATA)>
<!ELEMENT tamaþo - - (gramo | kilo | tenedor sopero | tenedor pequeþo | docena | una pizca)
<!ELEMENT ingred - - (#PCDATA)>
<!ELEMENT preparacion - - (paso+)>
<!ELEMENT paso - O (#PCDATA & p+)>
<!ATTLIST paso (opcional) #IMPLIED>
]>
Ya tenemos, pues, un DTD conformado para establecer nuestras etiquetas de marcaje, que aplicaremos para referirnos a los diferentes elementos de contenido del documento. El lenguaje SGML proporciona una sintaxis necesaria para realizar las diferentes declaraciones de elementos. AsÚ, todo sistema basado en SGML puede interpretar su significado al declarar los elementos con la marca <!ELEMENT. A partir de aquÚ se deben ir declarando los diferentes subelementos que configurarÃn, en este caso, nuestro recetario. #PCDATA (Parsed Character Data) significa que el elemento definido de esta manera contiene cualquier carÃcter vÃlido.
El HTML considera actualmente tres tipos diferentes de DTD: el DTD de nivel 2 de HTML de la IETF, el DTD de nivel 3 de HTML del W3C y el DTD Mozilla de Netscape.
El contenido del documento hace referencia a la informaciµn que contiene el documento en sÚ mismo. èste incluye los elementos fÚsicos, como por ejemplo los tÚtulos, los pÃrrafos, los menºs, las tablas, etc. El mÕtodo para identificar y definir los diferentes elementos se denomina marcaje, que delimita los diferentes elementos con etiquetas de inicio y final. èstas empiezan con "<etiqueta>" y acaban con "</etiqueta>". El contenido està inmerso dentro de estas etiquetas, que son definidas por las declaraciones de elementos de los DTD, que describirÃn quÕ es lo que cada elemento podrà contener, es decir, el modelo de contenido. Siguiendo la estructura de nuestro ejemplo, una pÃgina marcada segºn los elementos admitidos en el DTD RCP es:
<RECETA>
<P>Los <ORIGEN REGION="sudamerica">orÚgenes de este plato se han perdido a lo largo del tiempo</ORIGEN>.
Su preparaciµn es muy <DIFICULTAD>fÃcil</DIFICULTAD>, y requiere sµlo <TIEMPO>55<TIEMPO> minutos en total. Resulta ademÃs una receta muy econµmica, ya que podemos hacer mÃs de <PORCIONES TAMAîO="grande">6</PORCIONES> porciones generosas, ideales para acompaþar cualquier merienda de verano.</P>
<L-INGREDIENTES>
<P>Para hacer el puding de dulce de leche, necesitamos:</P>
<ITEM><CANT>una</CANT> <TAMAîO>docena<TAMAîO> <INGRED>de huevos</INGRED></ITEM>, <ITEM><CANT>un</CANT> <TAMAîO>kilo<TAMAîO> de <INGRED>dulce de leche</INGRED></ITEM> y <ITEM><CANT>3</CANT> <TAMAîO>cucharadas soperas<TAMAîO> de <INGRED>azºcar</INGRED></ITEM> para hacer el caramelo. AdemÃs, si queremos, podemos aþadir al sabor <ITEM NECES="opcional">trocitos de banana</ITEM>, <ITEM NECES="opcional">pasas de Corinto</ITEM> o <ITEM NECES="opcional">nueces</ITEM> y cubrirlo con <ITEM NECES="opcional">chocolate</ITEM>.</P>
</L-INGREDIENTES>
<PREPARACION>
<PAS><P>En primer lugar, tenemos que mezclar la docena de huevos y el dulce de leche hasta que se forme una mezcla suave y sin grumos.</P>
<P>Cuando hayamos batido los huevos, podemos hacer el caramelo y cubrir toda la bandeja, despuÕs de haberle aþadido toda la mezcla. Mientras hacemos eso, calentamos el horno.</P></PAS>
<PAS><P>Un vez que hemos preparado el recipiente, le vertemos la masa (pueden aþadirse las <ITEM NECES="opcional">nueces</ITEM>) y lo dejaremos en el horno sobre otro recipiente al baþo marÚa.</P></PAS>
<PAS><P>En estos momentos, el horno tiene que estar muy caliente.</P></PASO
<PAS>Un vez que han pasado <TIEMPO>30</TIEMPO> minutos, podemos retirarlo y, poco despuÕs, ponerlo en la nevera.<PAS>
</PREPARACION>
</RECETA
En el proceso de etiquetado del documento, hemos hecho referencia a las declaraciones de elementos contenidas en nuestro DTD RCP, que pertenecen a una serie de clases dadas por nosotros, y asÚ la tipografÚa del documento depende del DTD y no del documento. De esta manera, si en algºn momento se necesita ampliar o cambiar alguna declaraciµn, los documentos que contengan las directrices de esta clase seguirÃn a la perfecciµn el nuevo estÃndar, sin tener que hacer modificaciones para cada documento, en este caso una receta. Una vez que tenemos nuestro documento acabado, es posible generar sistemas de bºsqueda que respondan a las cualidades de nuestra informaciµn y no al texto en sÚ, como por ejemplo, ¢quÕ recetas de cocina oriental tenemos?, ¢quÕ recetas incluyen el azºcar como ingrediente?, ¢quÕ postres puedo hacer en un tiempo no superior a 40 minutos?
Gracias al marcaje de los documentos con etiquetas regidas por un DTD que sigue las directrices de SGML, las bºsquedas pueden ser mucho mÃs correctas, ya que se especificarÃn por contenidos y no por cadenas de caracteres o palabras como hasta ahora. èsta es una de las caracterÚsticas que hacen pensar en el XML como un lenguaje que solucione los actuales problemas de la informaciµn generada con etiquetas de HTML.
EL SGML consigue la independencia de la plataforma y el procesador de texto. Normalmente, cuando queremos traspasar un documento creado con un procesador de textos, como Word, a otro de un fabricante distinto, nos encontramos con problemas de cµdigo o interpretaciµn, lo cual no ocurre con SGML. Dado que no se trata de un producto comercial, sino que es un estÃndar universal, el usuario no se ve limitado a una aplicaciµn o un software especÚfico. Esto es lo que intentµ solucionar el HTML, aunque se ha quedado pequeþo para solucionar otros problemas como por ejemplo la recuperaciµn de la informaciµn.
Tal y como hemos comentado con anterioridad, el SGML no especifica la forma en que tiene que verse el documento, y como al fin y al cabo los documentos deben exportarse para ser visualizados, cada lenguaje o producto derivado de SGML define diferentes mecanismos para realizar la transiciµn entre las entidades de la clase y la versiµn fÚsica tipografiada.
En este sentido, hay que remarcar el esfuerzo que representµ la especificaciµn DSSSL (Document Style Semantics and Specification Language), una directiva que la ISO aprobµ como fase final en 1996 y, que define un lenguaje basado en "Scheme", funcional y parecido a LISP, con el cual es posible hacer programas para proporcionar apariencia a una clase de documentos, tanto en papel como en pantalla. Por su lado, el Departamento de Defensa de los Estados Unidos CALS emprendiµ una iniciativa propia de estÃndar, conocida como OS (Output Specification), que permite al usuario crear un DTD de formato denominado FOSI (Formatting Output Specification Instance), para estandarizar el formato externo de los documentos.
