


3. El comportamiento de compra
![]()
La investigación del cliente interno se hizo a partir de un estudio cuantitativo en el que la información de base para analizar se obtuvo a partir de un cuestionario estructurado aplicado a una muestra de 531 visitantes del centro con suficiente poder de compra. Se optó por escoger sólo a aquellos individuos con edades comprendidas entre los 18 y los 64 ańos, ya que el gerente del centro consideraba que fuera de este intervalo los clientes ya no tenían, para él, el suficiente poder de compra como para ser considerados poder real y potencial de compra.
La muestra se seleccionó a partir de la aplicación de un sistema de muestreo probabilístico en el que los individuos eran escogidos de forma aleatoria por tránsito de visitantes del centro en diferentes puntos de muestreo. Es decir, los entrevistadores encargados de conseguir la información estaban situados en las diferentes puertas del centro comercial por donde los visitantes podían salir, y éstos eran escogidos de manera aleatoria y sistemática (uno de cada tres individuos). La realización de este trabajo de campo se distribuyó en tres semanas y en diferentes días y horas de la semana para garantizar que todos los visitantes del centro estuvieran representados.
Para garantizar esta representatividad en la elección de la muestra y utilizar los recursos únicamente indispensables, se hizo necesario escoger cuatro días que fuesen los más representativos de la semana (lunes, jueves, viernes y sábado), en las horas del día que había más afluencia (de 12 a 14:30 y de 18:30 a 21:30 h) y desde cualquier punto por donde el visitante podía pasar (por tanto, cualquier puerta por la que podía salir).


Figura 1. Distribución de frecuencias simples de las variables de muestreo
PUNTO PUNTO DE MUESTREO
Value Label Value Frequency Percent Valid Cum
Percent Percent
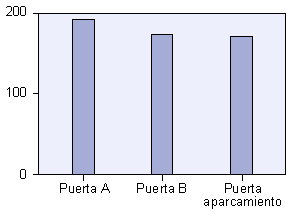
Puerta A 1.00 189 35.6 35.6 35.6
Puerta B 2.00 172 32.4 32.4 68,0
Puerta aparcamiento 3.00 170 32.0 32.0 100.0
------- ------- -------
Total 531 100.0 100.0
Valid cases 531 Missing cases 0
- - - - - - - - - - - - - - - - - - - - - - - - - - - - -
D_A DIA DE LA ENTREVISTA
Value Label Value Frequency Percent Valid Cum
Percent Percent
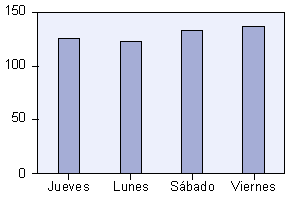
Lunes 1.00 126 23.7 23.7 23.7
Jueves 2.00 126 23.7 23.7 47.5
Viernes 3.00 141 26.6 26.6 74.0
Sábado 4.00 138 26.0 26.0 100.0
------- ------- -------
Total 531 100.0 100.0
Valid cases 531 Missing cases 0
- - - - - - - - - - - - - - - - - - - - - - - - - - - - -
HORARIO HORARIO
Value Label Value Frequency Percent Valid Cum
Percent Percent
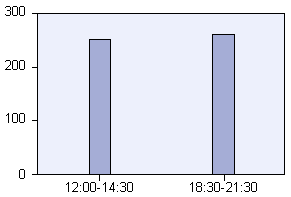
12:00 a 14:30H 1.00 261 49.2 49.2 49.2
18:30 a 21:30H 2.00 270 50.8 50.8 100.0
------- ------- -------
Total 531 100.0 100.0
Valid cases 531 Missing cases 0
Como primera aproximación al análisis de los datos, se hizo un análisis descriptivo. En este sentido, en la figura número 1 se puede ver la distribución aproporcional de la muestra en las variables de muestreo escogidas en el estudio. Prácticamente se distribuyó a partes iguales el mismo número de entrevistas por puerta (un tercio por puerta), por día (una cuarta parte por día) y por horario de visita (una mitad por la mańana y la otra por la tarde). En los histogramas siguientes también podemos ver la distribución de la muestra:
A pesar de que en toda la muestra la distribución era aproximadamente idéntica, a partir de las tablas de contingencia de las figuras número 2.1, 2.2 y 2.3 se pueden observar ciertas diferencias de perfil de los visitantes en las variables de muestreo inicial.
Figura 2.1. Tabla de contingencia: horario de entrevista por edad del entrevistado
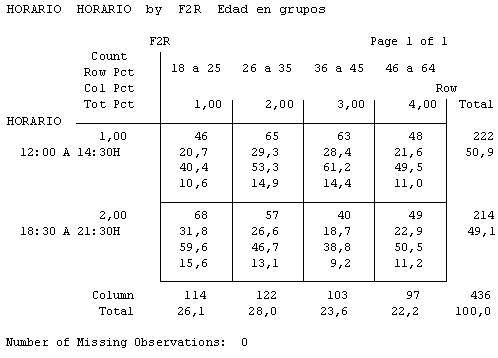
Figura 2.2. Tabla de contingencia: día de entrevista por edad del entrevistado
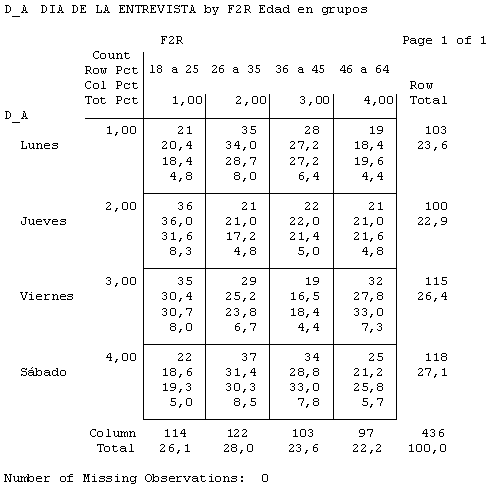
Figura 2.3. Tabla de contingencia: punto de muestreo por edad del entrevistado
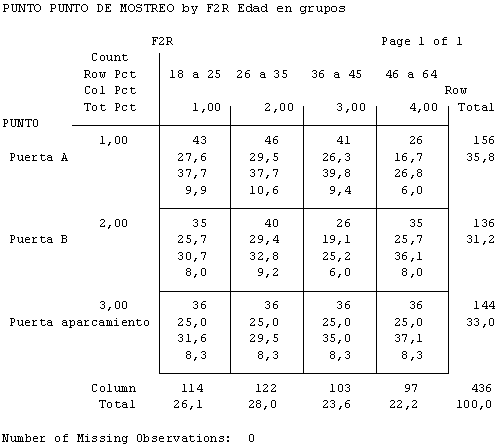
Con las tablas de contingencia anteriores podíamos observar que, comparativamente, los más jóvenes iban al centro por la tarde (59,6%), y más los jueves y viernes que los otros días. Y los de mediana edad (36 a 45 ańos), por ejemplo, iban más por la mańana (61,2%) y accedían al centro por el aparcamiento (35%) y por la puerta principal (puerta A, 39,8%).
Sin embargo, al seńor Ivars no sólo le interesaba el perfil de su cliente en datos básicos, el gerente quería ir más allá y conocer de manera profunda el comportamiento de compra de su cliente o visitante porque era lo que realmente le podía aportar información relevante para decidir su estrategia de marketing. Una de las informaciones más valiosas que esperaba obtener del estudio era el recorrido de su cliente, es decir, conocer los establecimientos donde compraba habitualmente y aquéllos en los que no compraba.
Era preciso descubrir cuáles de los establecimientos, tiendas o franquicias no mostraban un grado de atractivo suficiente para el visitante y pensar en un posible rediseńo del medio de comercialización del centro.
Figura 3. Frecuencia multirrespuesta de las variables p14_m1 a p14_m23
Group $ESTA establecimientos del centro donde compra
(Value tabulated = 1)
Pct of
Pct of Pct of Pct of
Dichotomy label Name Count Responses Cases
HIPERMERCADOS P14_M1 341 13.7 64.2
CAF REST FFOOD P14_M2 339 13.6 63.8
PAPELERIA PRENSA P14_M3 65 2.6 12.2
BANCOS CAJAS P14_M4 71 2.9 13.4
TIENDAS DE ROPA P14_M5 334 13.4 62.9
TIENDAS COMPLEM P14_M6 112 4.5 21.1
HOGAR DECORACION P14_M7 66 2.7 12.4
CINES P14_M8 235 9.4 44.3
ALIMENTACION P14_M9 44 1.8 8.3
JOYERIA P14_M10 22 0.9 4.1
TINTORERIA P14_M11 86 3.5 16.2
TIENDA ANIMALES P14_M12 34 1.4 6.4
FOTOGRAFIA P14_M13 50 2.0 9.4
SERVICIOS LUDICOS P14_M14 21 0.8 4.0
ELECTR INFOR P14_M15 64 2.6 12.1
COSMETICA P14_M16 28 1.1 5.3
TIENDA TELEFONIA P14_M17 21 0.8 4.0
MUSICA P14_M18 42 1.7 7.9
DEPORTES P14_M19 60 2.4 11.3
OPTICA P14_M20 32 1.3 6.0
TIENDA JUGUETES P14_M21 66 2.7 12.4
PARQUE INFANTIL P14_M22 36 1.4 6.8
APARCAMIENTO P14_M23 319 12.8 60.1
----- ----- -----
Total responses 2488 100.0 468.5
0 missing cases; 531 valid cases
Evidentemente, cada visitante iba al centro no sólo para ir a uno solo de sus establecimientos, sino que, una vez hecha la visita, este cliente iba a más de un establecimiento. Por lo que respecta a la media, cada cliente visitaba aproximadamente cinco establecimientos del centro.
A partir de los datos que se muestran en la tabla de frecuencias multirrespuesta número 3, se puede observar que gran parte de los clientes utilizaban el hipermercado (64,2%), las cafeterías, restaurantes y establecimientos de comida rápida (63,8%), las tiendas de moda (62,9%) y el aparcamiento (60,1%). Otro servicio que también era muy utilizado, aunque por un menor porcentaje de clientes, era el cine. Este hecho detectaba un posible punto débil del centro, ya que en la mayoría de los centros con cine éste se configura como una de las locomotoras del centro, junto con el hipermercado.
Evidentemente, esta afluencia de público a los diferentes establecimientos se observaba con muchas diferencias según las características de nuestros clientes. Por ejemplo, si construimos una nueva tabla de contingencia en la que observamos la distribución de los clientes que compraban en los establecimientos según el género (figura número 4), nos damos cuenta de que, comparativamente y de manera relativa, había más mujeres que hombres que compraban en establecimientos como el hipermercado, la tintorería, tiendas de complementos y de decoración o las de alimentación, entre otras, y que los hombres eran más asiduos de los establecimientos de telefonía móvil o de los servicios lúdicos.
Figura 4. Subtabla 1. Tabla de contingencia de los establecimientos donde compran según el género de los entrevistados
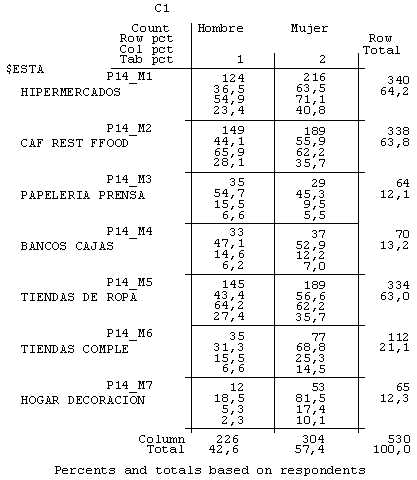
Figura 4. Subtabla 2. Tabla de contingencia de los establecimientos donde compran según el género de los entrevistados
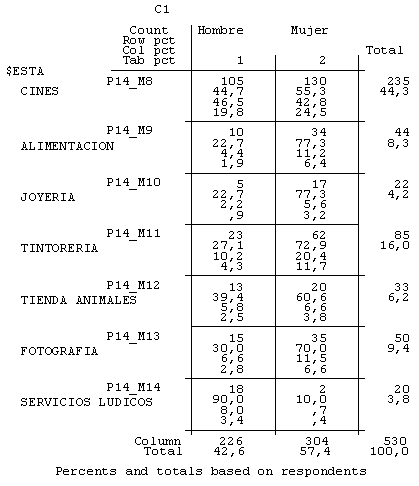
Figura 4. Subtabla 3. Tabla de contingencia de los establecimientos donde compran según el género de los entrevistados
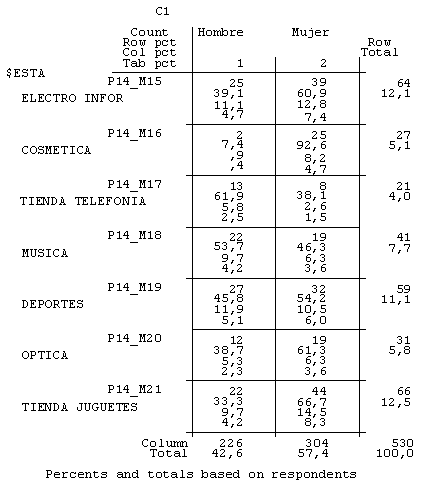
Figura 4. Subtabla 4. Tabla de contingencia de los establecimientos donde compran según el género de los entrevistados
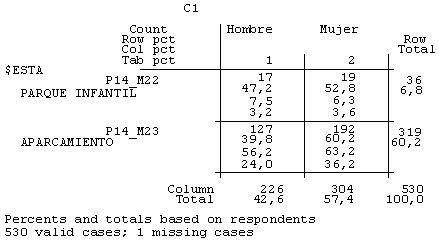
No obstante, el Sr. Ivars no conseguía apreciar suficientes diferencias entre el género de los individuos o entre la edad de los individuos o cualquier otra variable de clasificación básica como para poder emprender acciones de marketing diferenciadas para cada uno de estos públicos.
Los participantes en el proceso de análisis sugerimos al Sr. Ivars que tratase de aislar, segmentar, a sus clientes según los establecimientos donde compraban. Para él resultaba extremadamente interesante poder comprobar algunas de sus hipótesis sobre el comportamiento de compra de los clientes.
Sostenía que había una parte de clientes que sólo visitaban el centro por el hipermercado y, aunque iban también a otros establecimientos del centro, el más importante para ellos, aquello que realmente los motivaba a ir al centro comercial, era comprar en el hipermercado.
De la misma forma, estaba convencido de que tenía visitantes prácticamente exclusivos del cine y que éstos eran bastante homogéneos entre ellos.
La mejor manera de comprobar que realmente había diferentes tipologías de visitantes según el establecimiento donde compraban era intentando segmentar a los clientes en grupos homogéneos (dentro del mismo grupo) y a la vez muy heterogéneos (entre los diferentes grupos) con respecto a los establecimientos donde compraban habitualmente.
Para llegar a una solución de este tipo, se aplicó un análisis tipológico no jerárquico partiendo de la información observada anteriormente, es decir, de los establecimientos donde compraba cada cliente.
Partiendo de una matriz de datos en la que cada individuo se clasificaba de forma dicotómica según si compraba o no en cada establecimiento del centro, podíamos aplicar un análisis tipológico buscando las proximidades entre los individuos con respecto a su perfil de visita de los diferentes establecimientos.
Partiendo de las hipótesis iniciales del Sr. Ivars, se trató de segmentar a los visitantes del centro en sólo dos grupos y de forma libre para comprobar si realmente existían las dos tipologías propuestas por el gerente:
 | Los compradores mayoritarios de hipermercado y otros establecimientos, y |
| los visitantes del cine y de algún otro establecimiento, pero de manera minoritaria. |
A continuación se muestra el resultado obtenido de aplicar un análisis tipológico, también llamado análisis cluster no jerárquico de manera libre y en dos grupos.
Figura 5. Análisis cluster no jerárquico de dos grupos con centros de gravedad libres
* * * * * * * * * Q U I C K C L U S T E R * * * * * * * * * *
Initial Cluster Centers.
Cluster P14_M1 P14_M2 P14_M3 P14_M4 P14_M5 P14_M6
1 .0000 .0000 .0000 .0000 .0000 .0000
2 1.0000 1.0000 1.0000 1.0000 1.0000 1.0000
Cluster P14_M7 P14_M8 P14_M9 P14_M10 P14_M11 P14_M12
1 .0000 .0000 .0000 .0000 .0000 .0000
2 1.0000 1.0000 1.0000 1.0000 1.0000 1.0000
Cluster P14_M13 P14_M14 P14_M15 P14_M16 P14_M17 P14_M18
1 .0000 .0000 .0000 .0000 .0000 .0000
2 1.0000 1.0000 1.0000 1.0000 1.0000 1.0000
Cluster P14_M19 P14_M20 P14_M21 P14_M22 P14_M23
1 .0000 .0000 .0000 .0000 1.0000
2 1.0000 .0000 1.0000 1.0000 .0000
- - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - -
Convergence achieved due to no or small distance change.
The maximum distance by which any center has changed is .0855
Current iteration is 5
Minimum distance between initial centers is 4.6904
Iteration Change in Cluster Centers
1 2
1 1.2959 1.9092
2 .0188 .4915
3 .0408 .6077
4 .0524 .4075
5 .0240 .1803
* * * * * * * * * * * Q U I C K C L U S T E R * * * * * * * * *
Final Cluster Centers.
Cluster P14_M1 P14_M2 P14_M3 P14_M4 P14_M5 P14_M6
1 .6207 .6099 .0948 .1056 .5841 .1056
2 .7761 .8209 .2985 .3134 .9403 .9403
Cluster P14_M7 P14_M8 P14_M9 P14_M10 P14_M11 P14_M12
1 .0560 .3966 .0539 .0237 .1078 .0323
2 .5821 .7612 .2836 .1642 .5224 .2687
Cluster P14_M13 P14_M14 P14_M15 P14_M16 P14_M17 P14_M18
1 .0409 .0259 .0647 .0129 .0280 .0496
2 .4627 .1194 .5075 .3134 .1194 .2687
Cluster P14_M19 P14_M20 P14_M21 P14_M22 P14_M23
1 .0668 .0431 .0884 .0517 .5884
2 .4179 .1642 .3731 .1791 .6866
- - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - -
Number of Cases in each Cluster.
Cluster unweighted cases weighted cases
1 464.0 464.0
2 67.0 67.0
Missing 0
Valid cases 531.0 531.0
El resultado demostró que de los dos grupos que había, uno compraba prácticamente en todos los establecimientos y el segundo (el más numeroso) se comportaba como la media del mercado, es decir, compraba principalmente en el hipermercado.
Dado que el resultado del análisis sólo coincidía en parte con las hipótesis del gerente del centro, se optó por explotar la posibilidad de buscar más de dos grupos entre los que pudieran tener lugar los que intuitivamente el Sr. Ivars pensaba que había.
Así, se procedió a comprobar en cuántos grupos realmente se segmentaban sus clientes. De nuevo se llevó a cabo un análisis tipológico no jerárquico en tres, cuatro, cinco, seis y siete grupos y se pudo comprobar que la segmentación encontrada de cinco grupos era la que mejor reflejaba la situación de su centro comercial. En el ámbito estadístico era el que mejor formaba unos grupos homogéneos dentro de cada grupo y más heterogéneos entre los mismos.
A continuación se muestran los resultados obtenidos en el análisis cluster de cinco grupos. La tabla de contingencia que resulta de cruzar los cinco segmentos encontrados a partir del análisis tipológico muestra que los grupos resultantes tienen características muy similares dentro de los mismos grupos.
Figura 6. Tabla de contingencia de los cinco grupos encontrados con el análisis cluster, con centros de gravedad libres por las variables utilizadas para crear los grupos (establecimientos utilizados del centro comercial)
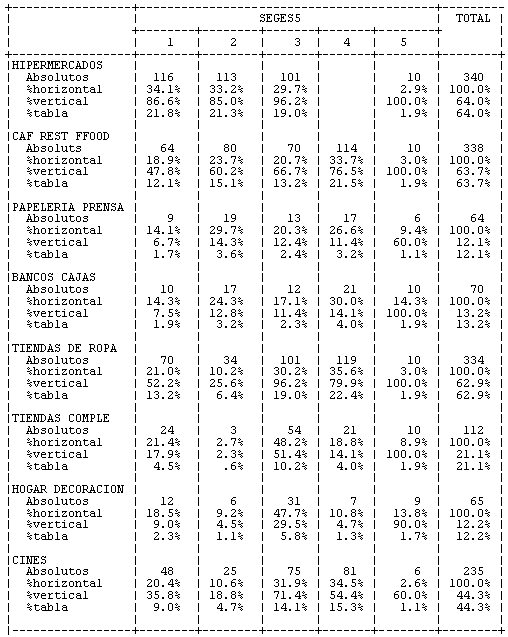
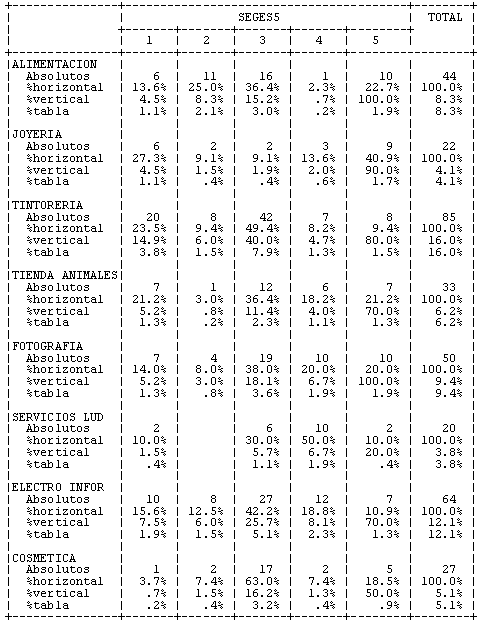
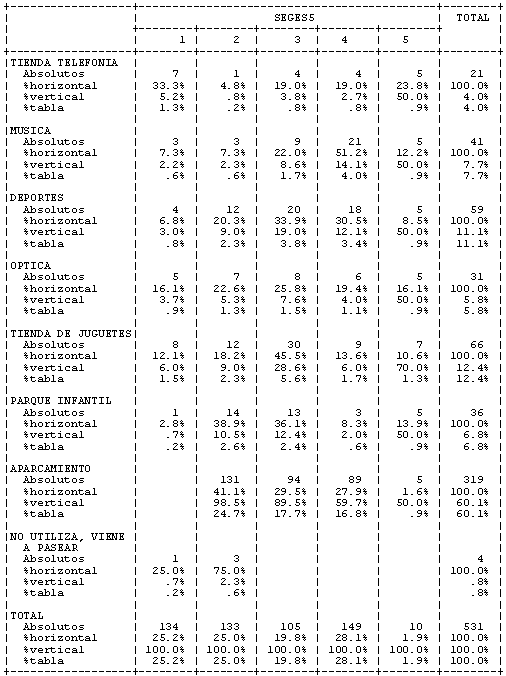
El resultado del análisis cluster y la tabla de contingencia posterior nos muestran cuatro grupos bien definidos y un quinto grupo muy similar al grupo 2, en el que prácticamente la mitad o más de sus componentes son usuarios de los establecimientos y servicios del centro comercial. De esta manera podemos observar en la tabla de contingencia lo siguiente:
| El grupo 1 se caracteriza porque prácticamente todos sus integrantes compran habitualmente en el hipermercado pero no utilizan el aparcamiento. |
| El segundo grupo, además de comprar principalmente en el hipermercado, utiliza el aparcamiento. |
| El tercer grupo está compuesto por clientes que prácticamente visitan todas las tiendas del centro; son lo que podríamos llamar compradores intensivos (heavy users). |
| Casi todos los componentes del cuarto grupo, además de no comprar en el hipermercado, compran en tiendas de moda y toman algo en los bares, cafeterías o restaurantes. |
| El quinto grupo es muy similar al tercer grupo de los compradores intensivos, pero sólo representa un 2% de los clientes, que en términos absolutos correspondería a diez personas de la muestra, grupo no lo bastante grande para analizar y extraer conclusiones sólidas. |
Encontrarnos con un quinto grupo con insuficiente base muestral como para tener entidad propia como tal generaba un problema analítico. Pero había una solución para dicho problema: tratar de reasignar los diez individuos de este grupo en alguno de los cuatro restantes. Podíamos hacer esta operación de manera totalmente subjetiva, es decir, a partir del conocimiento que teníamos del mercado y a partir de los resultados obtenidos en la tabla de contingencia, asignar los individuos del grupo 5 al grupo 3, ya que, en principio, es el que más se le parece. No obstante, había una posibilidad técnicamente más correcta, que consistía en utilizar el análisis discriminante múltiple para reasignar los componentes del grupo quinto a uno de los otros grupos que tuviera el perfil más similar según los establecimientos donde compraba, y eso es lo que hicimos.
El primer paso para reasignar a los individuos es dejar como valor perdido (missing value) la categoría de la variable que los asigna al grupo quinto, y el análisis discriminante dará automáticamente la supuesta pertenencia de estos individuos a otro grupo.
Figura 7. Distribución de frecuencias simple de los cinco grupos con el quinto grupo reasignado a valor perdido
SEGES5
Valid Cum
Value Label Value Frequency Percent Percent Percent
1 134 25.2 25.7 25.7
2 133 25.0 25.5 51.2
3 105 19.8 20.2 71.4
4 149 28.1 28.6 100.0
. 10 1.9 Missing
------- ------ -------
Total 531 100.0 100.0
Valid cases 521 Missing cases 10
Figura 7. Análisis discriminante múltiple para asignar los valores perdidos al grupo más similar
Following variables will be created upon successful
completion of the procedure:
GRP --- Predicted group for analysis 1
- - - - - D I S C R I M I N A N T A N A L Y S I S - - - - -
On groups defined by SEGES5
531 (Unweighted) cases were processed.
10 of these were excluded from the analysis.
10 had missing or out-of-range group codes.
521 (Unweighted) cases will be used in the analysis.
Number of cases by group
Number of cases
SEGES5 Unweighted Weighted Label
1 134 134.0
2 133 133.0
3 105 105.0
4 149 149.0
Total 521 521.0
Group means
SEGES5 P14_M1 P14_M2 P14_M3 P14_M4 P14_M5 P14_M6
1 .86567 .47761 .06716 .07463 .52239 .17910
2 .84962 .60150 .14286 .12782 .25564 .02256
3 .96190 .66667 .12381 .11429 .96190 .51429
4 .00000 .76510 .11409 .14094 .79866 .14094
Total .63340 .62956 .11132 .11516 .62188 .19578
SEGES5 P14_M7 P14_M8 P14_M9 P14_M10 P14_M11 P14_M12
1 .08955 .35821 .04478 .04478 .14925 .05224
2 .04511 .18797 .08271 .01504 .06015 .00752
3 .29524 .71429 .15238 .01905 .40000 .11429
4 .04698 .54362 .00671 .02013 .04698 .04027
Total .10749 .43954 .06526 .02495 .14779 .04990
SEGES5 P14_M13 P14_M14 P14_M15 P14_M16 P14_M17 P14_M18
1 .05224 .01493 .07463 .00746 .05224 .02239
2 .03008 .00000 .06015 .01504 .00752 .02256
3 .18095 .05714 .25714 .16190 .03810 .08571
4 .06711 .06711 .08054 .01342 .02685 .14094
Total .07678 .03455 .10940 .04223 .03071 .06910
SEGES5 P14_M19 P14_M20 P14_M21 P14_M22 P14_M23
1 .02985 .03731 .05970 .00746 .00000
2 .09023 .05263 .09023 .10526 .98496
3 .19048 .07619 .28571 .12381 .89524
4 .12081 .04027 .06040 .02013 .59732
Total .10365 .04990 .11324 .05950 .60269
Classification results -
No. of Predicted Group Membership
Actual Group Cases 1 2 3 4
------------------- ------ ----- ----- ------- ------
Group 1 134 117 0 0 17
87.3% .0% .0% 12.7%
Group 2 133 2 110 3 18
1.5% 82.7% 2.3% 13.5%
Group 3 105 4 1 98 2
3.8% 1.0% 93.3% 1.9%
Group 4 149 0 0 0 149
.0% .0% .0% 100.0%
Ungrouped cases 10 0 0 10 0
.0% .0% 100.0% .0%
Percent of "grouped" cases correctly classified: 90.98%
Classification processing summary
531 (Unweighted) cases were processed.
0 cases were excluded for missing or out-of-range
group codes.
531 (Unweighted) cases were used for printed output.
531 cases were written into the working file.
Como se puede observar en la matriz llamada de confusión (classification results) del análisis discriminante llevado a cabo, los componentes del grupo 5 que hemos pasado a valores perdidos (ungrouped cases) quedan reasignados al grupo 3. Hemos podido comprobar que la solución que habríamos aplicado haciendo caso a nuestra subjetividad y experiencia habría sido una solución idéntica a la encontrada por la estadística.
A continuación se muestra la distribución de frecuencias simple de la nueva variable de segmentación fruto de la reasignación de los individuos del antiguo grupo 5 al grupo 3.
Figura 8. Distribución de frecuencias simple de la nueva variable creada después de la reasignación de los individuos del grupo 5 al grupo 3
SEGES5N Segmentacióm clientes por establecimientos
Value Label Value Frequency Percent Valid Cum
Percent Percent
Hiper+No parking 1.00 123 23.2 23.2 23.2
Hiper+Parking 2.00 111 20.9 20.9 44.1
Heavy user 3.00 111 20.9 20.9 65.0
Moda+Cafe 4.00 186 35.0 35.0 100.0
------- ------- -------
Total 531 100.0 100.0
Valid cases 531 Missing cases 0
Como se puede apreciar en la figura 8, y después de analizar el perfil de cada grupo según los establecimientos del centro donde compraba (figura 6), los grupos se podían bautizar de la manera siguiente:
| Grupo 1: compradores del hipermercado que no utilizan el aparcamiento (probablemente porque residen muy cerca del centro). |
| Grupo 2: compradores del hipermercado que utilizan mayoritariamente el aparcamiento. |
| Grupo 3: compradores intensivos, prácticamente compran en todas las tiendas y utilizan todos los servicios del centro. |
| Grupo 4: compradores de productos de moda que, además, suelen tomar algo en los bares, cafés o restaurantes del centro. |
A pesar de tener características de comportamiento de compra lo bastante diferenciadoras para caracterizar los diferentes segmentos encontrados, era preciso estudiar a fondo cómo era cada uno de éstos para intentar, en el futuro, adaptarse a sus demandes más específicas.
A continuación se muestra el perfil de estos segmentos:
| por edad (con medidas de centro y dispersión), |
| por género (con una tabla de contingencia), y |
| por tiempo que tardan en llegar al centro (con una tabla de contingencia por intervalos y una tabla con medias y desviaciones para la variable continua). |
Figura 9. Tabla de medias de edad de los entrevistados para cada segmento encontrado
- - Description of Subpopulations - -
Summaries of F2 Edad
By levels of SEGES5N Segmentación clientes por establecimientos
Variable Value Label Sum Mean Std Dev Variance Cases
For Entire Population 18559.00 34.9510 12.0939 146.2617 531
SEGES5N 1.00 Hiper+No parking 4789.00 38.9350 12.6275 159.4548 123
SEGES5N 2.00 Hiper+Parking 4261.00 38.3874 10.4926 110.0940 111
SEGES5N 3.00 Heavy user 4035.00 36.3514 10.9890 120.7572 111
SEGES5N 4.00 Moda+Cafe 5474.00 29.4301 11.2758 127.1437 186
Total Cases = 531
Figura 10. Tabla de contingencia de género por segmentos encontrados
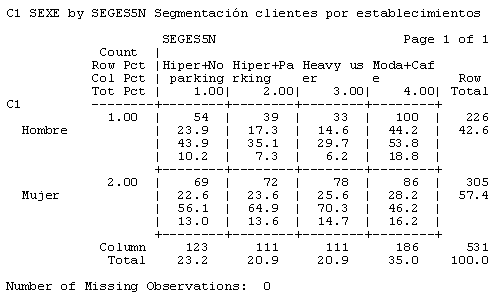
Figura 11. Tabla de contingencia del tiempo que tarda en llegar al centro (en intervalos) por segmentos encontrados
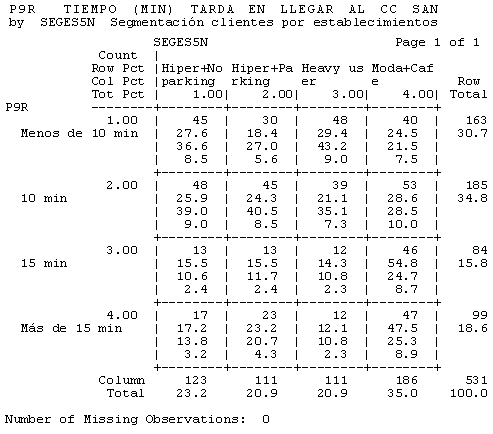
Figura 12. Tabla de medias de tiempo que tarda en llegar al centro por segmentos encontrados
- - Description of Subpopulations - -
Summaries of P9N Tiempo (min) tarda en llegar al C.C. SAN
By levels of SEGES5N Segmentación clientes por establecimientos
Variable Value Label Mean Std Dev Cases
For Entire Population 12.8569 10.1926 531
SEGES5N 1.00 Hiper+No parking 11.6829 10.1014 123
SEGES5N 2.00 Hiper+Parking 12.8559 9.7690 111
SEGES5N 3.00 Heavy user 9.6937 5.9296 111
SEGES5N 4.00 Moda+Cafe 15.5215 11.7741 186
Total Cases = 531
