


4. La satisfacción de los clientes con el centro
![]()
A pesar de saber que por lo general las diferencias en el comportamiento de compra de los clientes del centro se basaba principalmente en aspectos del merchandising del centro (la compra en los establecimientos), había que determinar hasta qué punto éstos estaban o no satisfechos con la oferta comercial, el nivel de precios que ofrecíamos, las promociones y ofertas, la calidad de los establecimientos, la ambientación del centro, etc.
En el estudio se optó por medir la satisfacción que tenían los clientes con el centro comercial, y no sólo de forma general, sino también específica, con toda una serie de aspectos que confeccionaban la calidad del servicio del centro. La satisfacción se medía en un cuestionario a partir de una serie de preguntas en las que el cliente tenía que valorar en una escala de 0 a 10 su satisfacción con los "ítems" de servicio del centro.
El grado de satisfacción obtenido en general mostraba un buen ajuste de la oferta del centro y la calidad de servicio a las expectativas del cliente. La satisfacción general se situaba en 7,2 en una escala de 0 a 10. Este valor no era una puntuación mala considerando, además, que el valor de la moda era el 7 y el coeficiente de asimetría indicaba una concentración de los resultados en valores altos de la distribución.


Figura 13. Distribución de frecuencias simple de la satisfacción general con el centro
P35 GRADO DE SATISFACCION GENERAL
Value Label Value Frequency Percent Valid Cum
Percent Percent
2.00 2 .4 .4 .4
3.00 5 .9 .9 1.3
4.00 6 1.1 1.1 2.5
5.00 15 2.8 2.8 5.3
6.00 93 17.5 17.6 22.9
7.00 185 34.8 35.0 57.8
8.00 165 31.1 31.2 89.0
9.00 39 7.3 7.4 96.4
10.00 19 3.6 3.6 100.0
. 2 4 Missing
------- ------ -------
Total 531 100.0 100.0
Mean 7.244 Std err .053 Median 7.000
Mode 7.000 Std dev 1.229 Variance 1.510
Kurtosis 1.956 S E Kurt .212 Skewness -.559
S E Skew .106 Range 8.000 Minimum 2.000
Maximum 10.000 Sum 3832.000
Valid cases 529 Missing cases 2
Aparte de la satisfacción general, la calidad del servicio percibida por los clientes se medía mediante un grupo más numeroso de aspectos y atributos que eran valorados de manera muy diferente por éstos. La satisfacción o insatisfacción en estos aspectos podían dar directrices al gerente del centro sobre qué aspectos había que mejorar.
En la figura siguiente podemos observar las puntuaciones en los aspectos específicos en los que los clientes valoraban el centro y mostraban su satisfacción o insatisfacción. Se muestra el valor de la media, la desviación típica, la moda y el número de entrevistados que han valorado cada uno de los aspectos siguientes:
 | El nivel de precios que ofrece el centro. |
| Las promociones y las ofertas que ofrecen los diferentes establecimientos del centro. |
| La variedad de establecimientos y tiendas del centro. |
| La calidad del aparcamiento. |
| La cantidad y calidad de establecimientos de restauración, bares y cafeterías. |
| Las actividades culturales y de entretenimiento que organiza el centro. |
| La información, seńalización y arquitectura interior. |
| El ambiente del centro (el hecho de sentirse a gusto comprando). |
| Los niveles de limpieza del centro. |
| La seguridad del centro. |
| Los lugares para entretener a los nińos en el centro. |
| La oferta de ocio del centro (cines, máquinas recreativas, etc.). |
| Los niveles de atención al cliente. |
| La accesibilidad y seńalización del exterior del centro. |
| La comunicación y publicidad que hace el centro. |
| Los servicios complementarios que ofrece el centro, como los cajeros automáticos, lavabos, etc. |
Aparte de la media y la moda, que nos dan idea de dónde se sitúa la puntuación media de los clientes, la desviación típica nos muestra el grado de homogeneidad de la valoración. Es decir, en aquellos aspectos en los que la desviación típica es elevada, los entrevistados no están todos de acuerdo en dar esta puntuación, mientras que en aquellos atributos en los que la desviación típica es baja, significa que aquella puntuación es muy homogénea, todos o casi todos los entrevistados están muy de acuerdo en dar esta valoración.
Figura 14. Tabla de medias de los aspectos específicos de satisfacción
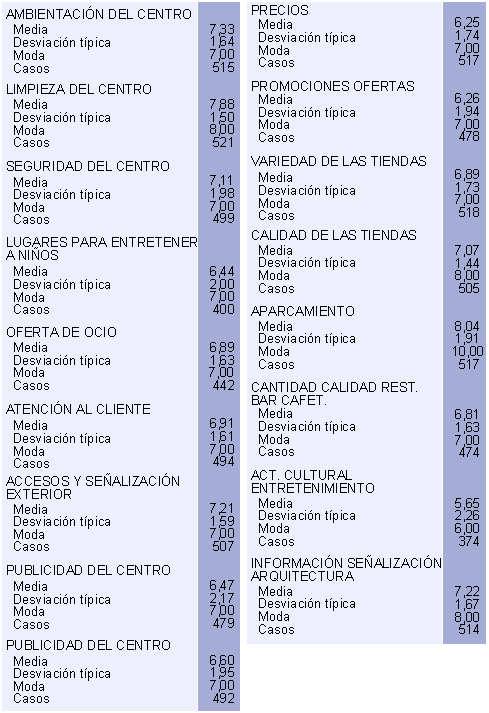
De los resultados de esta tabla podíamos concluir que los aspectos en los que nuestros clientes estaban más satisfechos hacían referencia a aspectos infrastructurales como el aparcamiento, la limpieza del centro, la ambientación, la seńalización interior/arquitectura, los accesos y la seńalización exterior y la seguridad.
Aquellos aspectos en los que el cliente ya no estaba tan satisfecho, es decir, que se encontraban por debajo de la media de satisfacción general (7,244), eran controlables por la táctica de marketing de la gerencia (calidad de la oferta de los establecimientos del centro, atención al cliente, variedad de oferta de los establecimientos, oferta de ocio, cantidad y calidad de restaurantes, bares y cafeterías, servicios complementarios, publicidad del centro, oferta de lugares para entretener a los nińos, promociones y ofertas, nivel de precios y actividades culturales y de entretenimiento que organiza el centro).
|
Aparcamiento |
8,04 |
Aspectos infraestructurales |
|
Limpieza del centro |
7,88 |
|
|
Ambientación del centro |
7,33 |
|
|
Información, seńalización, arquitectura |
7,22 |
|
|
Accesos y seńalización exterior |
7,21 |
|
|
Seguridad del centro |
7,11 |
|
|
Calidad de las tiendas |
7,07 |
Aspectos controlables por la táctica de marketing |
|
Atención al cliente |
6,91 |
|
|
Variedad de las tiendas |
6,89 |
|
|
Oferta de ocio |
6,89 |
|
|
Cantidad y calidad rest., bares, cafet. |
6,81 |
|
|
Servicios complementarios |
6,60 |
|
|
Publicidad del centro |
6,47 |
|
|
Lugares para entretener a los nińos |
6,44 |
|
|
Promociones, ofertas |
6,26 |
|
|
Precios |
6,25 |
|
|
Act. cultural, entretenimiento |
5,65 |
Ante estos resultados, poníamos al descubierto una posible mala gestión del centro en el ámbito del marketing. El Sr. Ivars necesitaba saber hasta qué punto era importante para el cliente cada uno de estos aspectos. Podíamos encontrarnos con que, a pesar de que las actividades culturales y de entretenimiento tenían muy mala valoración, quizá éstas no eran demasiado importantes para los clientes; o al contrario, aparte de ser un atributo mal valorado, el propio cliente podría encontrarlo importante en la generación de su satisfacción, lo cual todavía sería peor.
Analíticamente se aplicó una solución que pretendía determinar cuáles de estos atributos eran los que más contribuían a generar satisfacción global para los clientes. Se trataba de aplicar un análisis de regresión lineal múltiple en el que la variable que había que explicar, o variable endógena, fuese la satisfacción general de los individuos, y la satisfacción con cada aspecto específico fuesen las variables independientes y, por tanto, variables exógenas o explicativas.
Figura 15. Análisis de regresión lineal múltiple con la variable de satisfacción general como variable dependiente y aspectos específicos como variables independientes.
* * * * M U L T I P L E R E G R E S S I O N * * * *
Pairwise Deletion of Missing Data
Mean Std Dev Cases Label
P35 7.244 1.229 529 GRADO DE SATISFACCION GENERAL
P34_1 6.251 1.739 517 PRECIOS
P34_2 6.255 1.942 478 PROMOCIONES OFERTAS
P34_3 6.890 1.732 518 VARIEDAD DE LAS TIENDAS
P34_4 7.073 1.442 505 CALIDAD DE LAS TIENDAS
P34_5 8.037 1.906 517 APARCAMIENTO
P34_6 6.806 1.631 474 CANTIDAD CALIDAD REST BAR CAFET
P34_7 5.650 2.264 374 ACT CULTURAL ENTRETENIMIENTO
P34_8 7.216 1.673 514 INFORMACION SEŃALIZACION ARQUITECTURA
P34_9 7.328 1.638 515 AMBIENTACION DEL CENTRO
P34_10 7.881 1.499 521 LIMPIEZA DEL CENTRO
P34_11 7.106 1.985 499 SEGURIDAD DEL CENTRO
P34_12 6.440 2.002 400 LUGARES PARA ENTRETENER NIŃOS
P34_13 6.894 1.630 442 OFERTA DE OCIO
P34_14 6.909 1.606 494 ATENCION AL CLIENTE
P34_15 7.207 1.593 507 ACCESIBILIDAD SEŃALIZACION EXTERIOR
P34_16 6.472 2.171 479 PUBLICIDAD DEL CENTRO
P34_17 6.596 1.952 492 SERVICIOS COMPLEMENTARIOS
Minimum Pairwise N of Cases = 331
* * * * M U L T I P L E R E G R E S S I O N * * * *
Equation Number 1 Dependent Variable..P35
GRADO DE SATISFACCION GENERAL
Block Number 1. Method: Enter
P34_1 P34_2 P34_3 P34_4 P34_5 P34_6 P34_7 P34_8 P34_9 P34_10
P34_11 P34_12 P34_13 P34_14 P34_15 P34_16 P34_17
Multiple R .80311 Analysis of Variance
R Square .64499 DF Sum of Squares Mean Square
Adjusted R Square .62571 Regression 17 321.50598 18.91212
Standard Error .75191 Residual 313 176.95810 .56536
F = 33.45138 Signif F = .0000
* * * * M U L T I P L E R E G R E S S I O N * * * *
Equation Number 1 Dependent Variable..P35
GRADO DE SATISFACCION GENERAL
---------------- Variables in the Equation -------------
Variable B SE B Beta Tolerance VIF T Sig T
P34_1 .040408 .032134 .057190 .548322 1.824 1.257 .2095
P34_2 .040314 .030078 .063700 .502149 1.991 1.340 .1811
P34_3 .050211 .035935 .070755 .442304 2.261 1.397 .1633
P34_4 .182117 .044139 .213706 .422783 2.365 4.126 .0000
P34_5 .048076 .026821 .074553 .655638 1.525 1.792 .0740
P34_6 -.035356 .032544 -.046918 .608129 1.644 -1.086 .2781
P34_7 .055951 .025111 .103047 .530291 1.886 2.228 .0266
P34_8 .080788 .037089 .109941 .445214 2.246 2.178 .0301
P34_9 .035145 .039813 .046847 .402703 2.483 .883 .3781
P34_10 -.032547 .036353 -.039699 .576858 1.734 -.895 .3713
P34_11 .080972 .025965 .130750 .645223 1.550 3.119 .0020
P34_12 -.011156 .029156 -.018170 .503032 1.988 -.383 .7022
P34_13 .053736 .038282 .071277 .439884 2.273 1.404 .1614
P34_14 .017279 .035734 .022573 .520454 1.921 .484 .6290
P34_15 -.004235 .035931 -.005488 .523255 1.911 -.118 .9062
P34_16 .038941 .024561 .068794 .602458 1.660 1.586 .1139
P34_17 .168100 .028074 .266960 .570572 1.753 5.988 .0000
(Constante) 1.735518 .286842 6.050 .0000
A la vista del primer análisis de regresión, los resultados no fueron muy "satisfactorios", ya que topábamos con dos problemas:
- Algunas variables independientes no eran estadísticamente significativas para explicar el modelo encontrado por el análisis de regresión múltiple. Observable en la columna de la significación individual con el estadístico t-Student de las variables independientes en la figura anterior.
- El ajuste del modelo no era nada bueno, el coeficiente de determinación o R2, que es el principal indicador para conocer el grado de ajuste del modelo, no superaba el 70%, mínimo imprescindible para que el modelo sea normalmente considerado aceptable desde el punto de vista de la investigación de mercados.
El problema era que algunas variables independientes que intentaban explicar la variable de satisfacción general (dependiente) estaban excesivamente correlacionadas entre sí, lo que provocaba una "sobreinformación", de modo que la inclusión de estas variables generaba un peor ajuste que no si se las incluía en el modelo.
Esto podía ser debido a la incoherencia de las respuestas dadas a los diferentes atributos por parte de algunos clientes y, por tanto, el modelo no se podía ajustar lo bastante bien. Para solucionar este problema, había que determinar cuáles eran los clientes que habían respondido con más incongruencias para dejarlos temporalmente fuera del análisis.
En la figura siguiente se muestra un análisis de correlaciones y se observa que existe un gran número de variables correlacionadas entre sí:
Figura 16. Análisis de correlaciones entre variables independientes
|
|
|
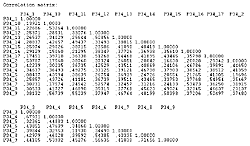
A la vista de la alta correlación entre algunas variables (subrayadas en la figura número 16), la mejor solución para este problema era, a partir de un análisis factorial de componentes principales, crear nuevas variables (que llamaríamos factores) que fuesen una combinación lineal de las variables originales y que entre éstas no hubiera correlación.
Figura 17. Análisis factorial de componentes principales con las variables independientes
- - - - - - - - - - F A C T O R A N A L Y S I S - - - - - - - - - -
Initial Statistics:
Variable Communality * Factor Eigenvalue Pct of Var Cum Pct
*
P34_1 1.00000 * 1 7.09664 41.7 41.7
P34_10 1.00000 * 2 1.50923 8.9 50.6
P34_11 1.00000 * 3 1.18868 7.0 57.6
P34_12 1.00000 * 4 .96304 5.7 63.3
P34_13 1.00000 * 5 .82193 4.8 68.1
P34_14 1.00000 * 6 .78424 4.6 72.7
P34_15 1.00000 * 7 .70185 4.1 76.9
P34_16 1.00000 * 8 .61730 3.6 80.5
P34_17 1.00000 * 9 .56515 3.3 83.8
P34_2 1.00000 * 10 .51133 3.0 86.8
P34_3 1.00000 * 11 .40898 2.4 89.2
P34_4 1.00000 * 12 .37218 2.2 91.4
P34_5 1.00000 * 13 .36684 2.2 93.6
P34_6 1.00000 * 14 .33157 2.0 95.5
P34_7 1.00000 * 15 .29654 1.7 97.3
P34_8 1.00000 * 16 .26876 1.6 98.8
P34_9 1.00000 * 17 .19574 1.2 100.0
PC extracted 11 factors.
Factor Matrix:
Factor 1 Factor 2 Factor 3 Factor 4 Factor 5 Factor 6 Factor 7
P34_1 .48756 .47423 .42982 -.20691 .09942 .27165 -.20205
P34_10 .59507 -.48712 .10667 .13685 .18104 -.16692 .10636
P34_11 .65611 -.29141 .31929 -.02154 .17061 -.20300 .27998
P34_12 .62275 .27473 -.30279 .34310 .31313 -.01151 .15755
P34_13 .65272 .03663 -.33123 .17756 -.01937 .45170 .05807
P34_14 .67307 -.10079 .03603 -.31128 .04173 .00663 .46925
P34_15 .59752 -.19927 -.15150 -.51611 -.03787 .36273 .05563
P34_16 .57579 .36476 -.34861 -.20133 -.32014 -.17766 .06328
P34_17 .70079 -.10713 -.33163 .19070 .14697 .19033 -.03121
P34_2 .53487 .39240 .49322 .20508 .24169 .15360 .00505
P34_3 .69963 .29505 .16053 .17968 -.37795 -.07472 .08497
P34_4 .72915 .02949 .25647 .07596 -.43101 -.06329 .10246
P34_5 .54803 -.40301 .00921 .38181 -.31092 .09877 -.17605
P34_6 .70986 -.09291 -.02656 .05011 .05730 -.14433 -.22009
P34_7 .57242 .44889 -.30132 -.07561 .16067 -.38788 -.07038
P34_8 .73092 -.19480 -.02680 -.24216 .04551 -.14010 -.37331
P34_9 .80897 -.19625 .07962 -.13736 .09802 -.06286 -.27089
- - - - - - - - - F A C T O R A N A L Y S I S - - - - - - - - -
Factor 8 Factor 9 Factor 10 Factor 11
P34_1 .08602 .24289 .13354 .10815
P34_10 .03764 .42495 .19227 -.11705
P34_11 .17448 -.20181 .00831 -.19459
P34_12 .16518 -.02992 -.15663 .06061
P34_13 .01632 .26435 -.09244 -.13112
P34_14 -.16951 .06805 -.01271 .40913
P34_15 .12888 -.21853 -.00336 -.17238
P34_16 .04411 .00678 .39813 -.07657
P34_17 -.24315 -.19133 .03247 .01089
P34_2 -.03279 -.25163 .13055 -.02401
P34_3 -.11139 .13354 -.21946 -.05795
P34_4 -.02981 -.07655 -.19563 -.10068
P34_5 .30659 -.14791 .21037 .28254
P34_6 -.53155 -.07495 .14627 -.03740
P34_7 .20861 -.03446 -.02651 .02521
P34_8 .02853 -.00670 -.30495 .14096
P34_9 .09394 .09643 -.02871 -.07717
Final Statistics:
Variable Communality * Factor Eigenvalue Pct of Var Cum Pct
*
P34_1 .91059 * 1 7.09664 41.7 41.7
P34_10 .92611 * 2 1.50923 8.9 50.6
P34_11 .87561 * 3 1.18868 7.0 57.6
P34_12 .85209 * 4 .96304 5.7 63.3
P34_13 .87229 * 5 .82193 4.8 68.1
P34_14 .98426 * 6 .78424 4.6 72.7
P34_15 .91626 * 7 .70185 4.1 76.9
P34_16 .93107 * 8 .61730 3.6 80.5
P34_17 .80463 * 9 .56515 3.3 83.8
P34_2 .88943 * 10 .51133 3.0 86.8
P34_3 .87200 * 11 .40898 2.4 89.2
P34_4 .85951 *
P34_5 .98599 *
P34_6 .89925 *
P34_7 .85295 *
P34_8 .90632 *
P34_9 .83000 *
- - - - - - - - - - F A C T O R A N A L Y S I S - - - - - -
VARIMAX rotation 1 for extraction 1 in analysis 1 -
Kaiser Normalization.
VARIMAX converged in 24 iterations.
Rotated Factor Matrix:
Factor 1 Factor 2 Factor 3 Factor 4 Factor 5 Factor 6 Factor 7
P34_1 .16542 .03972 .88299 .18704 .15351 -.02448 .11813
P34_10 .10327 .12012 .01985 .16374 .01831 .17737 .04863
P34_11 .23055 .11426 .09987 .18272 .03131 .09633 .20703
P34_12 .13219 .83958 .12771 .12534 .20135 .10437 -.00035
P34_13 .30038 .58671 .13275 .01546 .06083 .16909 .45449
P34_14 .20362 .14660 .12480 .15140 .13508 .15847 .21882
P34_15 .06904 .05845 .08000 .24584 .15593 .10750 .85573
P34_16 .23772 .11235 .09817 -.00111 .86661 .16849 .21718
P34_17 .10229 .49543 .01504 .12414 .08353 .59377 .30309
P34_2 .21566 .24604 .73228 -.04736 .00476 .25705 -.01794
P34_3 .80593 .23283 .23906 .13428 .21106 .14486 -.00458
P34_4 .77852 .06517 .14462 .18508 .12914 .14629 .16978
P34_5 .18654 .11888 .01505 .15038 .04244 .12170 .09780
P34_6 .22653 .08125 .12978 .27202 .17956 .80122 .05011
P34_7 .08935 .47361 .14140 .39288 .63750 .04045 -.06426
P34_8 .20938 .13671 .08756 .81095 .07904 .23159 .21715
P34_9 .20034 .14331 .24299 .56790 .15018 .24370 .28356
Factor 8 Factor 9 Factor 10 Factor 11
P34_1 .08903 -.02563 -.09384 .10717
P34_10 .86576 .18395 .17522 .15993
P34_11 .37587 .13188 .72013 .18885
P34_12 .07509 .08091 .15112 .10601
P34_13 .29309 .13670 -.27363 .04077
P34_14 .18893 .04460 .13296 .85803
P34_15 .04800 .08522 .15868 .19582
P34_16 .05180 .09354 -.04208 .11192
P34_17 .09414 .22847 .04873 .13504
P34_2 -.05442 .08374 .40889 .01789
P34_3 .09691 .06679 .01442 .11608
P34_4 .09436 .21314 .23494 .13252
P34_5 .19050 .91827 .08439 .03761
P34_6 .21803 .06793 .08404 .12073
P34_7 -.02084 -.08177 .15754 .04683
P34_8 .13613 .15302 .06859 .15748
P34_9 .40211 .18378 .16652 .04722
Factor Transformation Matrix:
Factor 1 Factor 2 Factor 3 Factor 4 Factor 5 Factor 6 Factor 7
Factor 1 .39945 .36199 .27889 .35058 .27510 .33632 .29117
Factor 2 .17155 .27180 .50910 -.15883 .43083 -.12000 -.21966
Factor 3 .26149 -.46254 .58198 -.01222 -.39458 -.12307 -.21597
Factor 4 .19940 .46951 -.06301 -.34179 -.25458 .15726 -.49406
Factor 5 -.65050 .41963 .23891 .14177 -.23856 .12739 -.09400
Factor 6 -.06189 .15790 .35176 -.31776 -.42830 -.00661 .61734
Factor 7 .17032 .18877 -.21741 -.58165 .01195 -.24928 .07906
Factor 8 -.15352 .18918 .06920 .14889 .17517 -.79077 .13505
Factor 9 .10231 .01396 .11578 .03563 .00560 -.26124 -.17714
Factor 10 -.41085 -.29495 .24948 -.46291 .49192 .23644 -.00736
Factor 11 -.20990 .03275 .10891 .19440 -.07072 -.06883 -.36106
Factor 8 Factor 9 Factor 10 Factor 11
Factor 1 .29231 .22970 .20034 .23833
Factor 2 -.45008 -.36105 -.14531 -.09989
Factor 3 .10482 .00821 .38627 .03304
Factor 4 .10816 .40475 .01553 -.33108
Factor 5 .18973 -.35094 .28408 .04199
Factor 6 -.13798 .16379 -.36876 -.00944
Factor 7 .11067 -.20377 .32255 .56872
Factor 8 .07220 .37061 .22441 -.21570
Factor 9 .68493 -.22911 -.58977 .07455
Factor 10 .26669 .31184 .03089 -.02048
Factor 11 -.27668 .41761 -.26351 .66687
11 PC EXACT factor scores will be saved.
Conseguimos un nuevo número de variables, concretamente once, que llamamos factores. Estos once factores eran variables nuevas incorrelacionadas entre sí y que eran combinación lineal de las diecisiete variables anteriores. Observando los resultados de las correlaciones rotadas de las variables originales con los once factores nuevos (subrayadas y en negrita en la matriz rotada de factores de la figura número 17), pudimos dar el siguiente nombre a cada factor, como se indica a continuación:
Factor 1: variedad y calidad de los establecimientos y tiendas del centro
Factor 2: oferta de ocio para todas las edades
Factor 3: precios, ofertas y promociones
Factor 4: arquitectura, seńalización y ambientación interior (espacio interior)
Factor 5: publicidad y actividades que organiza el centro
Factor 6: restauración y servicios complementarios (cantidad y calidad)
Factor 7: accesibilidad y seńalización exterior
Factor 8: limpieza del centro
Factor 9: aparcamiento
Factor 10: seguridad del centro
Factor 11: atención al cliente
A partir de estos factores que ya estaban incorrelacionados entre sí, podíamos repetir el análisis de regresión múltiple para intentar determinar cuáles eran los aspectos más importantes que determinaban la satisfacción de un cliente.
Antes de poder aplicar la regresión múltiple, había que estandarizar (normalizar) la variable dependiente, ya que los once factores estaban estandarizados.
Figura 18. Análisis de regresión lineal múltiple con los nuevos factores y la satisfacción general estandarizada
Number of valid observations (listwise) = 529,00
Variable MeanStd Dev Minimum Maximum Valid Label
N
P35 7,24 1,23 2,00 10,00 529 GRADO DE SATISFACCION GENERAL
The following Z-Score variables have been saved
on your working file:
From To Weighted
Variable Z-Score Label Valid N
-------- ------- ----- -------
P35 ZP35 Zscore: GRADO DE SATISFACCION GENERAL 529
* * * * M U L T I P L E R E G R E S S I O N * * * *
Pairwise Deletion of Missing Data
Mean Std Dev Cases Label
ZP35 ,000 1,000 529 Zscore: GRADO DE SATISFACCION GENERAL
FAC1_4 ,000 1,000 275 Variedad calidad tiendas
FAC2_4 ,000 1,000 275 Oferta ocio para todos
FAC3_4 ,000 1,000 275 Precios, ofertas y promociones
FAC4_4 ,000 1,000 275 Arquitec. seńaliz. ambiente int.
FAC5_4 ,000 1,000 275 Publicidad y eventos
FAC6_4 ,000 1,000 275 Restauración y servicios complemento
FAC7_4 ,000 1,000 275 Accesibil. y seńaliz. exterior
FAC8_4 ,000 1,000 275 Limpieza del centro
FAC9_4 ,000 1,000 275 Aparcamiento
FAC10_4 ,000 1,000 275 Seguridad del centro
FAC11_4 ,000 1,000 275 Atención al cliente
Minimum Pairwise N of Cases = 275
* * * * M U L T I P L E R E G R E S S I O N * * * *
Equation Number 1 Dependent Variable.. ZP35
Zscore: GRADO DE SATISFACCION
Descriptive Statistics are printed on Page 319
Block Number 1. Method: Enter
FAC1_4 FAC2_4 FAC3_4 FAC4_4 FAC5_4 FAC6_4
FAC7_4 FAC8_4 FAC9_4 FAC10_4 FAC11_4
Variable(s) Entered on Step Number
1.. FAC11_4 Atención al cliente
2.. FAC10_4 Seguridad del centro
3.. FAC9_4 Aparcamiento
4.. FAC8_4 Limpieza del centro
5.. FAC7_4 Accesibil. y seńaliz. exterior
6.. FAC6_4 Restauración y servicios complemento
7.. FAC5_4 Publicidad y eventos
8.. FAC4_4 Arquitec. seńaliz. ambiente int.
9.. FAC3_4 Precios, ofertas y promociones
10.. FAC2_4 Oferta ocio para todos
11.. FAC1_4 Variedad calidad tiendas
Multiple R ,80987 Analysis of Variance
R Square ,65589 DF Sum of Squares Mean Square
Adjusted R Square ,64149 Regression 11 179,71276 16,33752
Standard Error ,59875 Residual 263 94,28724 ,35851
F = 45,57105 Signif F = ,0000
------------------- Variables in the Equation --------------------
Variable B SE B Beta Tolerance VIF T Sig T
FAC1_4 ,412146 ,036172 ,412146 1,000000 1,000 11,394 ,0000
FAC2_4 ,312426 ,036172 ,312426 1,000000 1,000 8,637 ,0000
FAC3_4 ,238605 ,036172 ,238605 1,000000 1,000 6,596 ,0000
FAC4_4 ,240943 ,036172 ,240943 1,000000 1,000 6,661 ,0000
FAC5_4 ,204483 ,036172 ,204483 1,000000 1,000 5,653 ,0000
FAC6_4 ,228903 ,036172 ,228903 1,000000 1,000 6,328 ,0000
FAC7_4 ,206955 ,036172 ,206955 1,000000 1,000 5,721 ,0000
FAC8_4 ,153374 ,036172 ,153374 1,000000 1,000 4,240 ,0000
FAC9_4 ,241925 ,036172 ,241925 1,000000 1,000 6,688 ,0000
FAC10_4 ,208576 ,036172 ,208576 1,000000 1,000 5,766 ,0000
FAC11_4 ,104076 ,036172 ,104076 1,000000 1,000 2,877 ,0043
(Constante)-3,58951E-15 ,036106 ,000 1,0000
La solución aplicada demostraba claramente que no había correlación entre las diferentes variables (factores) introducidas en el modelo. De esta manera la significación de cada variable era perfecta, es decir, todas las variables introducidas en el modelo eran significativas. Esto podemos verlo en la columna de la significación de la T, en la que todas éstas son significativas al cien por cien.
No obstante, el indicador del coeficiente de determinación R2 no había mejorado su ajuste con respecto al modelo de regresión hecho con variables originales. Por tanto, lo que necesitábamos era mejorar el ajuste aplicando la solución que ya se había planteado anteriormente, que era intentar hacer los cálculos del modelo obviando a determinados individuos, que llamaremos outliers, por el hecho de que sus valoraciones eran excesivamente dispersas y se podía estar ante un problema de incoherencia en las respuestas de tales entrevistados.
La mejor manera que teníamos para detectar a los outliers era pedir al programa estadístico que nos mostrase para cada individuo las diferencias que se producían entre el modelo de regresión real observado y el modelo estimado.
La diferencia que hay entre el modelo real y el modelo estimado se denomina residuo. En el caso que nos ocupa, estos residuos han oscilado desde el valor –3,68 al valor +2,24, lo que indica que cuando el residuo es 0, el modelo estimado y el modelo real son el mismo para cada individuo.
Figura 19. Distribución de frecuencias simple de la variable residuo: diferencia entre la recta de regresión real y la estimada
RES_1 Residual
Value Label Value Frequency Percent Valid Cum
Percent Percent
-3,68925 1 ,2 ,4 ,4
-1,84178 2 ,4 ,7 1,1
-1,60984 1 ,2 ,4 1,5
-1,08131 1 ,2 ,4 1,8
-1,04287 1 ,2 ,4 2,2
-1,03029 1 ,2 ,4 2,5
-,97381 1 ,2 ,4 2,9
-,95739 1 ,2 ,4 3,3
-,95083 1 ,2 ,4 3,6
-,94545 1 ,2 ,4 4,0
-,87338 3 ,6 1,1 5,1
-,87220 1 ,2 ,4 5,5
-,86180 2 ,4 ,7 6,2
-,85187 2 ,4 ,7 6,9
-,84072 3 ,6 1,1 8,0
-,81353 2 ,4 ,7 8,7
-,76861 1 ,2 ,4 9,1
-,69652 1 ,2 ,4 9,5
-,67539 2 ,4 ,7 10,2
-,66187 1 ,2 ,4 10,5
-,65487 1 ,2 ,4 10,9
-,63670 1 ,2 ,4 11,3
-,60933 1 ,2 ,4 11,6
,64928 1 ,2 ,4 88,7
,66859 1 ,2 ,4 89,1
,67901 2 ,4 ,7 89,8
,68371 1 ,2 ,4 90,2
,71521 2 ,4 ,7 90,9
,73275 2 ,4 ,7 91,6
,73280 2 ,4 ,7 92,4
,74958 1 ,2 ,4 92,7
,76488 1 ,2 ,4 93,1
,76715 1 ,2 ,4 93,5
,81184 1 ,2 ,4 93,8
,82477 1 ,2 ,4 94,2
,85465 3 ,6 1,1 95,3
,89096 1 ,2 ,4 95,6
,94242 1 ,2 ,4 96,4
1,00013 2 ,4 ,7 97,1
1,08914 1 ,2 ,4 97,5
1,14428 1 ,2 ,4 97,8
1,20673 1 ,2 ,4 98,2
1,29090 1 ,2 ,4 98,5
1,37399 1 ,2 ,4 98,9
1,48843 1 ,2 ,4 99,3
1,78759 1 ,2 ,4 99,6
2,24751 1 ,2 ,4 100,0
, 256 48,2 Missing
------- ------ -------
Total 531 100,0 100,0
Valid cases 275 Missing cases 256
Observando la distribución de frecuencias de este residuo (figura 19), se eliminó al 8% de individuos que tenían el residuo más diferente con respecto al valor medio del residuo, tanto por encima como por debajo, es decir, por encima y por debajo de este valor medio.
Una vez identificados estos outliers, se repitió el modelo de regresión sin tenerlos en cuenta.
Figura 20. Análisis de regresión lineal múltiple eliminando al 16% de los entrevistados por considerarlos outliers.
BASE: ELIMINANDO RESIDUOS 8% POR CADA COLA
* * * * M U L T I P L E R E G R E S S I O N * * * *
Equation Number 1 Dependent Variable.. ZP35
Zscore: GRADO DE SATISFACCION
Descriptive Statistics are printed on Page 347
Block Number 1. Method: Enter
FAC1_4 FAC2_4 FAC3_4 FAC4_4 FAC5_4 FAC6_4
FAC7_4 FAC8_4 FAC9_4 FAC10_4 FAC11_4
Variable(s) Entered on Step Number
1.. FAC11_4 Atención al cliente
2.. FAC8_4 Limpieza del centro
3.. FAC1_4 Variedad calidad tiendas
4.. FAC10_4 Seguridad del centro
5.. FAC2_4 Oferta ocio para todos
6.. FAC3_4 Precios, ofertas y promociones
7.. FAC7_4 Accesibil. y seńaliz. exterior
8.. FAC4_4 Arquitec. seńaliz. ambiente int.
9.. FAC6_4 Restauración y servicios complemento
10.. FAC5_4 Publicidad y eventos
11.. FAC9_4 Aparcamiento
Multiple R ,91794 Analysis of Variance
R Square ,84261 DF Sum of Squares Mean Square
Adjusted R Square ,83452 Regression 11 167,90760 15,26433
Standard Error ,38283 Residual 214 31,36332 ,14656
F = 104,15243 Signif F = ,0000
-------------------- Variables in the Equation --------------------
Variable B SE B Beta Tolerance VIF T Sig T
FAC1_4 ,441589 ,025309 ,476808 ,984807 1,015 17,448 ,0000
FAC2_4 ,324106 ,024670 ,358279 ,988926 1,011 13,138 ,0000
FAC3_4 ,226243 ,026957 ,229401 ,984389 1,016 8,393 ,0000
FAC4_4 ,254541 ,026921 ,259194 ,978685 1,022 9,455 ,0000
FAC5_4 ,188930 ,025657 ,202148 ,975916 1,025 7,364 ,0000
FAC6_4 ,266547 ,025440 ,287745 ,975134 1,025 10,478 ,0000
FAC7_4 ,236184 ,025554 ,252998 ,981545 1,019 9,243 ,0000
FAC8_4 ,212471 ,027143 ,215153 ,973555 1,027 7,828 ,0000
FAC9_4 ,298656 ,026418 ,310936 ,972229 1,029 11,305 ,0000
FAC10_4 ,232347 ,026068 ,245258 ,971358 1,029 8,913 ,0000
FAC11_4 ,156007 ,026399 ,161631 ,983147 1,017 5,910 ,0000
(Constante) -,024078 ,025641 -,939 ,3488
Y el resultado, como nos muestra la salida estadística del ordenador (figura 20), mejoró el coeficiente de determinación R2 hasta un ajuste del 84%. Era un valor más que acceptable.
Por otro lado, también se puede ver que el modelo es globalmente significativo, dado que el valor del estadístico F, que sigue una distribución Fischer-Snedecor, sale 104,15 con una significación de 0,0 (menor que el nivel de significación, que habitualmente se fija en 0,05).
Este modelo era válido y, por tanto, lo que necesitábamos era interpretar correctamente los resultados del modelo y su aplicación. El modelo de regresión nos aportó la importancia de cada factor en la explicación de la satisfacción general del individuo y esta importancia se obtenía a partir de las "betas" del modelo de regresión por cada variable. Así, la variable más importante era la variedad y calidad de las tiendas y establecimientos del centro; la segunda, la oferta de ocio del centro para todo el mundo, el aparcamiento, la restauración, y así sucesivamente.
El modelo nos determina la importancia de todos los factores; de esta manera no nos indica que no haya factores que no sean importantes, sino que hay algunos menos importantes que otros. La tabla siguiente nos muestra la importancia relativa de cada factor, ordenados dichos factores de manera descendente, extraído de la figura 20, análisis de regresión lineal múltiple.
|
Importancia |
Factor |
|
47,68 |
Factor 1: variedad y calidad de los establecimientos del centro |
|
35,83 |
Factor 2: oferta de ocio para todas las edades |
|
31,09 |
Factor 9: aparcamiento |
|
28,77 |
Factor 6: restauración y servicios complementarios |
|
25,92 |
Factor 4: arquitectura, seńalización y ambientación interior |
|
25,30 |
Factor 7: accesibilidad y seńalización exterior |
|
24,53 |
Factor 10: seguridad del centro |
|
22,94 |
Factor 3: precios, ofertas y promociones |
|
21,52 |
Factor 8: limpieza del centro |
|
20,21 |
Factor 5: publicidad y actividades que organiza el centro |
|
16,16 |
Factor 11: atención al cliente |
Gracias al cálculo de las importancias de cada factor utilizando el modelo de regresión, el Sr. Ivars ya era capaz de determinar cuáles eran los aspectos del centro comercial Barcelona Glňries que había que mejorar. Sólo tenía que combinar la valoración de satisfacción media de cada aspecto con la importancia de este mismo para determinar si era un aspecto que había que mejorar o no.
Para poder combinar las satisfacciones medias de cada atributo, lo primero que se necesitaba era encontrar las valoraciones medias de cada nuevo factor que se había creado con el análisis factorial de componentes principales. A pesar de que es posible utilizar diferentes métodos para encontrar estas valoraciones, aplicando el principio de la parsimonia y utilizando el camino más simple, lo más sencillo era utilizar las medias aritméticas de cada variable que formaba el factor.
De todos modos, había factores que sólo estaban compuestos por un único atributo y, por tanto, la valoración media del factor era la misma que la del atributo, como por ejemplo el aparcamiento, la restauración, la accesibilidad exterior, la seguridad del centro, la limpieza del centro y la atención al cliente. El resto se tuvo que combinar: la variedad y calidad de los establecimientos del centro en los que la variedad estaba valorada por 518 clientes con una puntuación de 6,89 y la calidad de los establecimientos del centro, valorada por 505 clientes con una puntuación de 7,07. El resultado era una media aritmética de 6,98.
|
Importancia |
Valoración media |
Factor |
|
47,68 |
6,98 |
Factor 1: variedad y calidad de los establecimientos del centro |
|
35,83 |
6,68 |
Factor 2: oferta de ocio para todas las edades |
|
31,09 |
8,04 |
Factor 9: aparcamiento |
|
28,77 |
6,70 |
Factor 6: restauración y servicios complementarios |
|
25,92 |
7,27 |
Factor 4: arquitectura, seńalización y ambientación interior |
|
25,30 |
7,21 |
Factor 7: accesibilidad y seńalización exterior |
|
24,53 |
7,11 |
Factor 10: seguridad del centro |
|
22,94 |
6,25 |
Factor 3: precios, ofertas y promociones |
|
21,52 |
7,88 |
Factor 8: limpieza del centro |
|
20,21 |
6,11 |
Factor 5: publicidad y actividades que organiza el centro |
|
16,16 |
6,91 |
Factor 11: atención al cliente |
Con esta tabla resultante observamos claramente que la oferta de ocio y entretenimiento para todas las personas, adultos, jóvenes y nińos, era un aspecto que la gerencia del centro tenía que mejorar, ya que mostraba una importancia elevada para los clientes (35,83) y la media de satisfacción (6,68) del factor estaba claramente por debajo de la media de satisfacción global del centro (7,2). De forma similar, los servicios de restauración (la cantidad y la calidad de los restaurantes) merecían una atención especial por tener una importancia relevante y una valoración de satisfacción baja. El nivel de precios, ofertas y promociones y la publicidad y eventos que organiza el centro eran también aspectos que había que controlar, aunque tenían una importancia relativamente más baja que los otros dos factores.
Sin embargo, la variedad y la calidad de la oferta de los establecimientos del centro y el aparcamiento eran aspectos con los que los clientes estaban satisfechos y, además, les daban importancia como generadores de satisfacción.
Estaba claro, pues, que el centro presentaba importantes carencias en la oferta lúdica, ya que tanto la restauración como los lugares de ocio respondían a un comportamiento de compra menos funcional y más dirigido a la diversión.
Por lo que al marketing se refiere, era posible dar respuesta a esta demanda del mercado de dos formas.
| Una era en un ámbito tangible, es decir, había que mejorar la oferta lúdica mejorando la oferta a partir del incremento del número de restaurantes, bares, cafeterías, cines, salas de juegos, etc. Había que buscar nuevas ofertas más atractivas para los clientes actuales y potenciales del centro. |
| La segunda era la mejora de la oferta lúdica en un ámbito más intangible. Lo que había que hacer era mejorar, desde un punto de vista más perceptivo, la oferta lúdica del centro, es decir, había que conocer perfectamente los posibles valores negativos de la oferta y contrarrestarlos con pequeńas mejoras y con comunicación. Las valoraciones que los consumidores hacían de los productos tenían un gran componente de percepción; muchas veces las sensaciones no son demostrables empíricamente y son sólo impresiones que los consumidores tienen de los productos y las marcas. |
Los recursos limitados que el gerente del centro tenía lo llevaban a intentar mejorar en un primer momento la percepción que había del centro en términos de oferta lúdica. Pero, para poder llevar a cabo diferentes acciones de marketing encaminadas a esta mejora, había que conocer más a fondo cómo eran los clientes que valoraban negativamente la oferta lúdica.
żQuiénes eran los clientes que daban una valoración baja en la oferta de restaurantes, bares y en la oferta de ocio en general? żQué grupo de edad era mayoritario entre los clientes que estaban poco satisfechos con este tipo de oferta del centro? żDe qué zona geográfica del área de influencia del centro nos llegaban estos clientes, qué tipo de productos solían comprar, con qué frecuencia venían, etc.?
El primer paso que se dio para descubrir todos estos datos partió de un análisis multivariable que se llama AID, el detector automático de interacciones, que nos permitía conocer dónde se producían las mayores diferencias de valoración de algún índice o atributo de satisfacción según las diferentes características de los individuos. Por tanto, se aplicó un AID para explicar dónde se producían las diferencias en los atributos que hacen referencia a la oferta de ocio:
| la cantidad y la calidad de restaurantes, bares y cafeterías, |
| la oferta de ocio en general. |
Figura 21. AID. Detector automático de interacciones para explicar las diferencias en la valoración del atributo de cantidad y calidad de los restaurantes, bares y cafeterías.
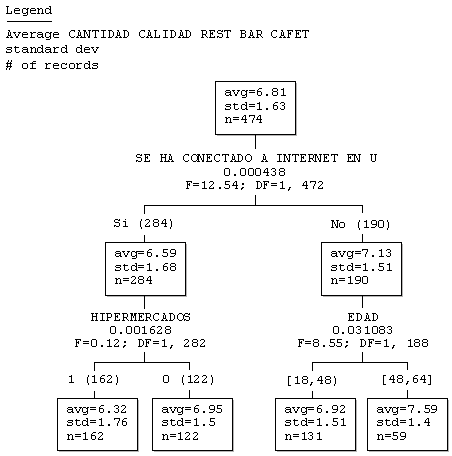
Lo que podemos observar mediante el análisis AID es que, en principio, los que no se han conectado a Internet durante el último mes son los que están más satisfechos con la cantidad y calidad de bares y restaurantes y, dentro de éstos, los mayores en edad son quienes están más satisfechos con la oferta de restauración.
Por el contrario, los más insatisfechos son aquellos que se han conectado a Internet durante el último mes y que van normalmente al hipermercado del centro.
Figura 22. AID. Detector automático de interacciones para explicar las diferencias en la valoración del atributo de la oferta de ocio.
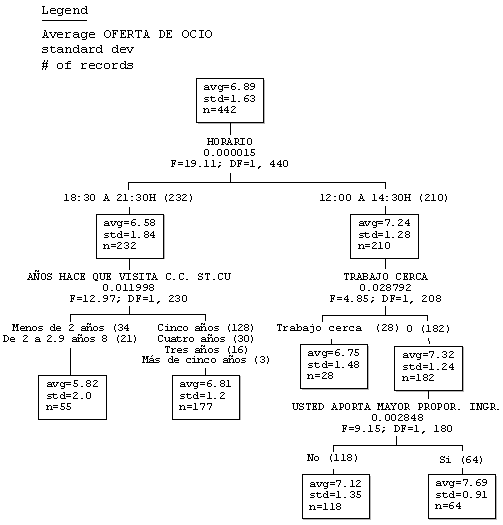
Los más insatisfechos con la oferta de ocio eran los visitantes del centro que solían ir a comprar a partir de las 18:30 h de la tarde, mientras que los más satisfechos eran los que compraban por la mańana.
En realidad, las actividades de ocio como, por ejemplo, ir al cine, se suelen hacer por la tarde y, por tanto, es normal que los clientes de la tarde sean más exigentes con este tipo de oferta. Además, esta satisfacción es inferior entre aquellos clientes que hace menos tiempo que son clientes del centro: su satisfacción está prácticamente un punto por debajo de la media de los clientes más antiguos.
Entre los clientes de la mańana, aquellos que suelen acudir al centro porque trabajan cerca y además son los cabezas de familia, la satisfacción es más alta, lógicamente porque son una tipología de clientes que sólo va al centro para comprar y no para divertirse. Fijémonos en que la satisfacción llega hasta 7,69, casi un punto más que la media de los clientes entre este tipo de visitantes.
De este modo, entre los clientes más satisfechos y los más insatisfechos hay prácticamente dos puntos de diferencia (de 5,8 a 7,7 sobre 10).
Lo que el director del centro, el Sr. Ivars, vio claro es que debía mejorar tanto de manera tangible la oferta de ocio como de manera intangible la comunicación sobre ésta, pero sobre todo entre los clientes más nuevos (que hace menos tiempo que compran en el centro) y que compran principalmente por la tarde y entre aquellos clientes del centro que son internautas y que utilizan sobre todo el hipermercado.
